
공지
지식만은 평등해야 한다.
1. 들어가기에 앞서 [본문]
2. 구상 1. 향후 포스팅 / 프로젝트 진행 계획 [본문]
3. 구상 2. 컨텐츠 획득 관련 [본문]
4. 구상 3. 이미지 생성 관련 [본문]
5. 구상 4. 번역 프로젝트 [본문]
6. 구상 5. 출판 프로젝트 [본문]
7. 구상 6. Apps on a Blog [본문]
8. 구상 7. 휴먼-컴퓨터 인터페이스 (HCI) [본문]
9. 구상 8. 지식의 본질에 대한 연구 [본문]
10. 끝맺음 [본문]
주요 업데이트: 지식이 무한함을 증명하기 위한 시도
마지막 수정: 25.03.13
1. 들어가기에 앞서 [목차]
처음에는 일기장처럼 시작한 블로그입니다 (since 2007). 그런데 이 블로그를 통해 저라는 사람이 특별해졌고, 이 블로그를 통해 세상과 소통하고 싶어졌습니다. 그러다가 2016년 이세돌과 알파고의 매치를 보면서 이 블로그에 인류의 지식에 대한 트리를 스케치하고 싶었습니다. 그리고 이제 이 프로젝트를 본격적으로 완성하고자 합니다.
§ 목적 1. 지식의 민주화를 실현
○ 더이상 교육이 평등하지 않기 때문에...
○ 더이상 교육이 희망과 꿈을 보여주지 않기 때문에...
○ 병들어 가는 대한민국에 새로운 변화를...
○ 사람들이 공부를 어려워하여 좌절하거나 불필요하게 많은 시간을 투자하는 경우가 많고,
○ 지식욕을 만족시키는 것에 대한 기쁨을 제대로 누리지 못한 경우도 많았으며,
○ 막대한 교육비용 지출이 대한민국을 병들게 하므로 강력한 대책이 강구됩니다.
○ 그런데, 모든 분야에 대한 최종적이고 최고의 지식 체계를 공개한다 해도 대한민국의 교육열이 낮아질 것인가?
○ 다만, 가용 지식의 다양성은 다원주의 사회와 관련되고, 이는 일원주의 사회 특유의 높은 교육열을 해소할 것이다.
○ 지식의 독점은 생각보다 빠르게 소진된다. 지식의 평등을 실현할 날이 그렇게 먼 일이 아닐 것이다.
○ 지식의 민주화는 사회 갈등을 감소시킨다.
○ 지식의 불평등은 계층 간 갈등을 야기한다.
○ 올바른 지식의 공개는 잘못된 지식을 바로 잡게 한다. 올바른 지식은 언제나 단순하고 명료하기 때문에
○ 비밀주의는 불필요한 환상을 야기한다.
○ 지식의 평등은 민초들의 힘을 강화하는 방법이다.
○ ChatGPT가 지식의 민주화를 실현하는 것처럼 보이지만, 지식의 격차를 끔찍하게 증가시킬지도 모른다고 몇몇 학자들은 주장하고 있다.
○ 결국 사람을 위한 지식의 민주화가 중요하다고 생각한다.
○ 아보카도중독자 님의 첨언
AI가 AI를 지배하는 시대에 자본주의의 붕괴는 가속화되고 자급자족 사회로의 회귀가 진행될 것이다. 이 시대에 뒤처지는 이들을 위해 지식의 민주화는 반드시 필요하다.
§ 목적 2. 인류의 인지 포화 상태의 방지
○ 특이점 도래 : 인류가 지식을 이해하는 속도보다 지식이 쌓이는 속도가 빨라지는 시점은 앞으로 50년 후로 예상됨
○ ChatGPT의 너무 이른 등장으로 그 시점이 더 빨라진 것 같다.
○ information explosion : 현재에도 IT 정보와 바이오 정보의 폭발적 증가가 우려됨
○ IT 정보 포화의 방지 : IT 산업계와 협력을 도모함
○ 바이오 정보 포화의 방지 : 연구계와 협력을 도모함. 유전자를 중심으로 한 DB 구성을 일단 계획
○ 어떻게 1인이 인류의 지식 총량을 모두 모을 수 있는가?
○ 해답 1. 크라우드 소싱 모델 : 다수에 의한 지식의 수집 및 공유의 비즈니스 모델 구축
○ 경제사를 공부하다 보면 알게 되는 가장 중요한 결론. 이 세계는 언제나 수확체증의 법칙을 보여주었다. 인구의 증가가 비가역적인 기술 발전을 일으켰고 사람들의 생활은 더 풍족해졌다. 그렇다면 지식도 공유할수록 사람들이 모일 것이고, 모여든 사람들이 더 많은 지식을 창출하지 않을까?
○ 현재 위키백과, Github, 네이버 지식in 등 공지의 BM 모델이 잘 알려져 있다.
○ 해답 2. AI 인공지능 모델 : 살아있고 진화하는 글에 대한 구상
○ 글은 살아있고 숨쉬는 생물이다. 그러니까 끊임없이 새로운 생각들을 채워주어야 한다.
○ 모든 사람은 글을 쓸 수 있으나 글에 생명을 불어넣는 것은 아무나 할 수 없으므로 경쟁이 없는 새로운 분야일 지도 모른다.
○ 해답 3. 소셜 네트워킹 모델 : 점 조직 형태의 네트워크 구축
○ 제가 생각하는 비즈니스 모델은 점 조직으로 구성된 형태입니다. 대기업에서 채택하는 수직적 계층은 개인의 자아실현 욕구가 강해진 현대에 적합하지 않다는 진단입니다. 수직적 계층보다는 일대일로 사적 계약을 형성하여 1인이 네트워킹의 중심이 되는 전략을 구상하고 있습니다. 이것이 최초부터 함께한 스타트업에서 제가 보고 느낀 점입니다.
○ 해답 4. 지식에 대한 통찰
○ core concept는 전체 지식 중 적은 비율로 존재한다는 점에서 착안
○ core concept를 모아둔 내용은 시험공부를 위한 요점노트 같은 것이라고 생각할 수 있을 듯
○ core concept의 정확한 정의를 이해하려면 정보이론의 surprisal을 참고
○ 다만, 코어 메타지식만 알려줘도 디테일은 ChatGPT가 알려줄 수 있어서 지식의 모든 디테일을 포괄할 수도 있을 것입니다.
§ 목적 3. 인류의 지식을 보전하기 위한 시도
○ 지식은 영원해야 한다.
○ 고대 로마 제국이 붕괴한 직후 로마 제국이 보유한 방대한 기술이 소실된 바 있음
○ 인류는 언제나 높은 확률로 멸종 시나리오를 직면하고 있음 : 지구 문명의 수명은 기껏해야 몇백 년 정도...
○ 기후변화
○ 핵전쟁
○ 소행성 충돌
○ 전염병 창궐
○ 인류와 AI의 대립
○ 현 블로그는 인류의 지식이 소실됐을 때 인류의 지식을 보전하기 위한 시도의 성격이 있음

Figure. 1. 애니 닥터스톤 일러스트
○ 블록체인의 가르침이 가르쳐 주듯이 지식을 공유하는 것은 지식을 영원하게 함
○ 물론, 인류의 멸종을 반드시 막을 것이고 이에 대비한 시나리오를 공유할 예정
○ 먼 훗날 외계 문명이 인류의 지식을 답습할 수 있게 완전하고 무결한 데이터 스토리지를 구상함
○ 혹은, 다른 행성에서 문명을 시작하기 위한 지식의 씨앗을 준비하는 과정
○ 즉, 수백 년쯤 뒤 외계 행성에 문명을 건설할 적에 만물 지식백과가 필요하지 않겠는가?
§ 목적 4. 지식 습득의 가속화
○ 음악도 템포가 빨라지는 게 유행하고 틱톡과 같이 빠르고 반복적인 동영상이 인기를 끄는데 지식을 빠르게 습득하는 형태가 미래지향적이지 않을까?
○ 저출산은 모든 선진국이 겪는 현상이다. 소수가 다수를 부양해야 하는 시대에 지식의 습득 속도는 빨라져야 한다.
○ 지식 습득의 가속화는 여성의 경력 단절을 해결할 좋은 대책일 수 있다.
○ 인간의 기억은 영원하지 않다. 전문가들도 잊어버린 지식을 빠르게 상기시킬 수 있는 지식 체계가 필요하지 않을까?
○ 지식 습득의 가속화는 먼 훗날 인간과 AI의 대립에서 인간 진영의 힘을 키우는 요인이 될 것이다.
○ 교육 비용의 증가로 청년들의 사회 진출이 늦어지고 있는데, 이 상황에서 지식 습득의 가속화가 필요하지 않겠는가?
○ 지식 습득의 가속화는 아직 도전이 끝나지 않은 그대에게 꼭 필요하지 않은가?

§ 목적 5. 지식이 무한함을 증명하기 위한 시도
○ 인간의 발전은 영원해야 하므로 : 인류가 영원하게 유지되지 못하더라도, 적어도 지식은 영원하다.
○ 양자를 단위로 하는 인간이 트랜지스터를 단위로 하는 AI를 이기는 분야는 지식의 양이 하나의 우주를 이루는 영역이므로
○ 아인슈타인은 십대 시절에 어머니에게 "성인이 되면 더 이상 연구할 주제가 없으면 어떡하죠?"라고 물었다고 한다. 하지만, 그는 양자역학과 상대성 이론을 탄생시켰다. 그렇다면, 지금은 어떤가?
○ 인간의 지식 총량을 무한까지는 아니더라도 크게 넓힐 수 있는 방법을 찾아냈다. (`인지의 지평선과 AI라는 돌파구`)
2. 구상 1. 향후 포스팅 / 프로젝트 진행 계획 [목차]
○ '25. 3월 中 대학교 수학 경시대회, 화학 문제 풀이
○ '25. 4월 中 해석학 포스팅 리뉴얼
3. 구상 2. 컨텐츠 획득 관련 (in progress) [목차]
2-1. 차세대 서치엔진 프로젝트 (in progress) : 서치엔진, AI
여기에서 모든 분야에 대한 컨텐츠를 생성할 수는 없을 것으로 보입니다. 그 이유는 1) 각 분야의 여러 전문가들을 모두 능가하는 전문성을 확보하는 것은 현재로서는 불가능에 가깝고, 2) 설령 인공지능을 통해 그것을 가능케 한다고 한들 신산업을 육성하지 못한 채 기존 일자리를 위협하는 것에 그치므로 바람직하지 않으며, 3) 깊은 개념을 빠짐 없이 모두 다루면 입문자들의 이해도를 크게 해칠 수 있기 때문입니다.
그래서 제가 선택한 전략은, 1) 비교적 쉽게 크롤링 가능한 지식들을 모으는 데에 집중하고 (2-1), 2) AI를 통해 컨텐츠를 생산하며 (2-2), AI 비서들로 하여금 비정형 지식들을 수집하도록 하고 (2-3), 4) 크라우드 소싱을 통해 대중들의 협력도 도모하는 것 (2-4)입니다.
이 서치엔진은 그래프 구조의 자료구조를 취하는 기존의 서치엔진과 리스트 구조의 위키백과와 달리 트리구조를 취하는 KMS(knowledge management system)라는 점에서 차별성이 있습니다. 저는 개인적으로 트리구조가 인간의 인지구조와 가장 닮아있다고 생각합니다. 그리고 회사에게 KMS를 제공해주는 private KMS나 정부에게 KMS를 제공해주어 정부 정책을 홍보하는 창구도 고려하고 있습니다. 은하수를 여행하는 히치하이커를 위한 '진짜' 안내서도 필요할 것 같습니다... 이를 통해 1) 지식을 가장 빠르게 습득하는 데 기여하고, 2) 지식의 일체성 (문법의 동일성 및 내용의 일관성이 있는 성질) 및 비중복성 (필요한 수준의 개념 중복까지만 허용하는 성질)을 보장하며, 3) 회사 내 의사소통을 빠르게 하고, 4) 특허 청구항의 권리범위 비교 등을 용이하게 할 수 있다고 생각합니다.
스타트업의 최초부터 함께하면서 제가 느낀 점은 지식의 일체성을 유지하는 게 생각보다 어렵다는 점입니다. 이와 관련하여 1) 서로 다른 날에 한 데이터 분석 결과가 다르면 안 되는데 달랐을 때 어떤 파라미터 때문에 다른지 몰랐다는 점, 2) 서로 다른 분야의 전문가들 간의 의사소통이 잘 이루어지지 않는다는 점, 3) 오직 어떤 지식을 처음으로 알게 된 순간만이 그 지식이 자신에게 새로운 지식이었음을 인지할 수 있다는 점을 목격했습니다. 그리고 3)과 관련하여, 저는 꽤 어릴 적부터 많은 신규 지식을 기록해 왔기 때문에 현재 수준의 트리를 구축할 수 있었지만 너무 많이 알고 있는 사람은 무엇이 새로운 지식인지 잘 모를 수도 있을 것입니다.
○ 종류 1. 다이제스트 위키 프로젝트 (Digest Wiki project) (not started)
○ 2-1에서 비교적 쉽게 크롤링 가능한 지식들을 모으는 것과 관련하여 위키백과를 제1의 타겟으로 선택했습니다. 번역 프로젝트의 종결과 함께 문득 든 생각. 예를 들면, 근두암종균이라는 단어는 영어로 Agrobacterium tumefaciens입니다. 만일 누군가가 Agrobacterium tumefaciens이 궁금했을 때 서치 엔진을 통해 제 블로그 내 DNA 테크놀로지와 관련된 게시물로 유입이 될 수 있을 것입니다. 그리고 그 자는 DNA 테크놀로지 포스팅에서 구체적으로 어떤 서브 카테고리에 Agrobacterium tumefaciens라는 단어가 배치되는지를 확인할 수 있을 것이고, 그 자의 궁금증을 어느 정도 해결해줄 수 있을 것입니다. 결국 사람들이 궁금해하는 것은 정보이고, 제가 제공할 수 있는 것은 맥락이라는 정보이며, 사람들에 대한 유인 수단은 용어(terminology)일 것입니다. 위키 프로젝트의 모든 페이지를 크롤링해서 일련의 전문용어 사전을 확보하는 작업이 조만간 개시될 것입니다.
○ 종류 2. 법은 만인 앞에서 평등하다. (not started)
○ 법은 그 효과가 평등해야 할 뿐만 아니라 그 이해도 평등해야 한다. 전 인류의 법적 성숙을 위하여 구상하고 있는 아이디어. 우리는 국가법령정보센터 등을 통해 우리나라의 모든 법조문을 확보할 수 있고, 이런 식으로 전 세계의 모든 법조문을 확보할 수 있습니다. 그리고 조문 내 인용 조항을 전부 모으면 모든 법조문의 상호 연결관계, 즉 네트워크를 확보할 수 있습니다. 그리고 클러스터링 알고리즘을 실행시키면 적절한 hierarchy를 확보할 수 있을 것입니다. 이로써 누구나 쉽게 법률적 지식을 빠르게 이해할 수 있을 것입니다.
Figure. 2. R로 쉽게 구현할 수 있는 클러스터링 결과
○ 대한민국의 법률이 1580개(2022 기준)가 있고, 헌법, 명령, 조례, 규칙 등이 있을 수 있으니 수천 개의 포스팅이 생성될 것
○ 미국은 주마다도 법률이 다르므로...
○ Chernoff face를 이용한다면 판사별로 소송 전략을 추천해줄 수 있지 않을까?

Figure. 3. Chernoff face
○ 종류 3. 북 네트워크 (complete)
○ 책의 양은 너무 방대하다. 모든 책들을 클러스터링한다면 어떤 책이 더 중요한지, 어떤 책을 더 먼저 읽어야 하는지 알 수 있을까?
○ 일단 아마존(amazon.com)에서 이미 시도는 해보았을 것으로 보입니다.
○ 간단하게는 상호 간 인용관계를 이용하여 책들에 관한 heatmap을 구현할 수는 있습니다. (ref)
○ LLM 알고리즘을 바탕으로 책들의 지도를 만들 수 있습니다. (ref)
○ 종류 4. OCR (image to text) (in progress)
○ GPT-4V와 같은 large multi-modal modeling을 사용하여 이를 구현할 수 있습니다.

Figure. 4. GPT-4V의 예시
○ 이를 통해 이미지 데이터 및 출판물을 손쉽게 디지털 데이터로 변환할 수 있습니다.
○ 종류 5. 업계 표준 부여 시스템 (in progress)
각 분야의 제1의 전문가들의 자료들을 링크하여 업계 표준을 부여하는 것입니다. 제1의 전문가들을 누구로 선정하는지는 내부 평가에 따를 것이며, 시간에 따라 변할 것으로 보입니다. 특허와 유사한 독점적 기능을할 것이며 업계 표준을 지정받기 위한 서류 제출을 받습니다.
○ 종류 6. 파운데이션 모델 (in progress)
크롤링 된 지식의 무더기 속에서 의미 있는 정보를 추출해주는 파운데이션 모델. 시퀀싱 데이터에서 유용한 스코어를 뽑아내는 아이디어에서 시작해 블로그에도 접목할 수 있다는 발상을 통해 시작하게 된, 저를 설레게 하는 프로젝트입니다. 어쩌면 저만의 트랜스포머 모델을 만들어야 할 수도 있을 것 같습니다.
2-2. AI 데이터 생성 (in progress) : AI
○ 개요
○ 2022년 7월에 공개된 AlphaFold2 데이터베이스. 약 2억 개의 단백질 구조 데이터베이스로 50년 간 인류가 실험적으로 밝혀낸 단백질 구조보다 1000배 많은 단백질 구조를 1년 안에 생성하였다. AI가 인지 수준을 넘어선 방대한 데이터를 생성하는 게 결국 컨텐츠 획득에 있어 나아가야 하는 방법이 아닐까. 그리고 그것을 관리하고 인출하기 위한 데이터베이스가 중요해지지 않을까. 그게 이 블로그의 최종 형태가 될 것이라고 생각한다.
○ 즉, AI를 통해 자동으로 데이터를 생성하고, 생성된 데이터를 curation하는 전략
○ 방법 1. AI 기반 데이터베이스 (in progress)
○ 예 1. 생체고분자 라이브러리 : 각종 3D 모델 정보를 프론트엔드 상에 업로드
○ 예 2. 동종/이종 간 리간드-수용체 상호작용 결합 친화도 데이터베이스 : 24년 8월 이내에 종료 목표
○ 방법 2. LLM으로 주어진 포스팅의 태그를 자동으로 생성 (complete)
○ 태그는 hallucination에 크게 영향을 받지 않으므로 괜찮음
○ 방법 3. 문제은행 AI (in progress)
○ 생성형 AI 모델로 새로운 지식을 생성할 수 있다면 문제를 생성하는 AI, 즉 문제은행 AI도 쉽게 만들 수 있음
○ 예 1. TOEFL speaking problem
○ 예 2. 유기화학 명명법 10만제 (complete)
○ 예 3. 유기화학 이성질체 2300제 (complete)
○ 예 4. 유기화학 분광학 100제 (complete)
○ AI에 의해 생성된 문제를 학습 데이터로 하면 문제를 푸는 AI, 즉 가설이나 이론을 생성하는 AI를 구현할 수 있음
○ 구체적으로는, 문제를 푸는 AI는 LLM 컴포넌트들의 직병렬 회로라고 추정 (ref)
○ 위 아이디어를 구현하여 2024년 Nature DeepMind에서 IMO 문제를 푸는 AI가 등장 (ref)
2-3. 진화하고 살아있는 AI (in progress) : 크롤링, NLP
○ 기본 아이디어
○ 인간은 동물처럼 입으로 밥을 먹지만 동물과 달리 머리로 지식을 먹음
○ 음식물을 소화하기 위해 단량체로 분해해야 하듯이 글을 소화하기 위해 개념으로 분해해야 함
○ 물론 문장과 문장 간의 관계인 맥락이 무의미한 것은 아니고 개념을 더 확실하게 만들어 준다는 의미가 있음
○ 생물체가 끊임없이 대사하며 살아가고 진화하듯이 지식도 살아있고 진화할 수 있어야 함
○ 방법 1. 스스로 지식을 크롤링하는 모델 (not started)
○ 전제 : 지식 체계가 기존에 무결성, 비중복성, 일체성, 간결성을 가지고 있음
○ 무결성 : 내용의 오류가 없는 성질
○ 비중복성 : 필요 이상의 중복이 없는 성질
○ 일체성 : 방대한 글이 하나의 흐름으로 연결되는 성질
○ 간결성 : 문체가 군더더기 없이 간결한 성질
○ 1단계. 문장 단위로 쪼갬
○ 2단계. 자체적으로 이해 가능한 문장들만 추림 : 지시대명사(예 : 이, 그, 저)가 있다고 일괄적으로 무시할 것은 아님
○ 3단계. 코어 지식(core concept)에 대한 문장들만 추림
○ 4단계. 분야에 따라 나눔 : 법, 경제, 과학 등
○ 5단계. 각 분야에서 구체적인 포스팅으로 연결 : 각 분야 내에서는 포스팅이 일체성이 있는 경우가 많음
○ 6단계. 각 포스팅 내 구체적으로 몇 번째 라인인지를 연결 : 중복이 없으면 그 지점에 해당 코어 지식 삽입
○ 중간 결론 : 다시 그 지식 체계는 무결성, 비중복성, 일체성, 간결성을 가지고 있음
○ 최종 결론 : 그 지식 체계는 영원히 무결성, 비중복성, 일체성, 간결성을 가지고 있음 (수학적 귀납법)
○ 스스로 지식을 크롤링하는 모델 모식도 : 스스로 지식을 크롤링하는 모델은 간단히 말하면 꼬리에 꼬리를 물어 개념을 수정하고 확장해 가는 패러다임입니다. 저는 이 방식이 인간의 인지와 닮아 있고, 딥러닝 알고리즘의 핵심 원리인 back propagation algorithm이 적용된다고 생각합니다. 이런 통찰을 기초로, 사람은 감각기관뿐만 아니라 중추신경계에서도 딥러닝을 사용하는 것이라고 생각하고 있습니다.
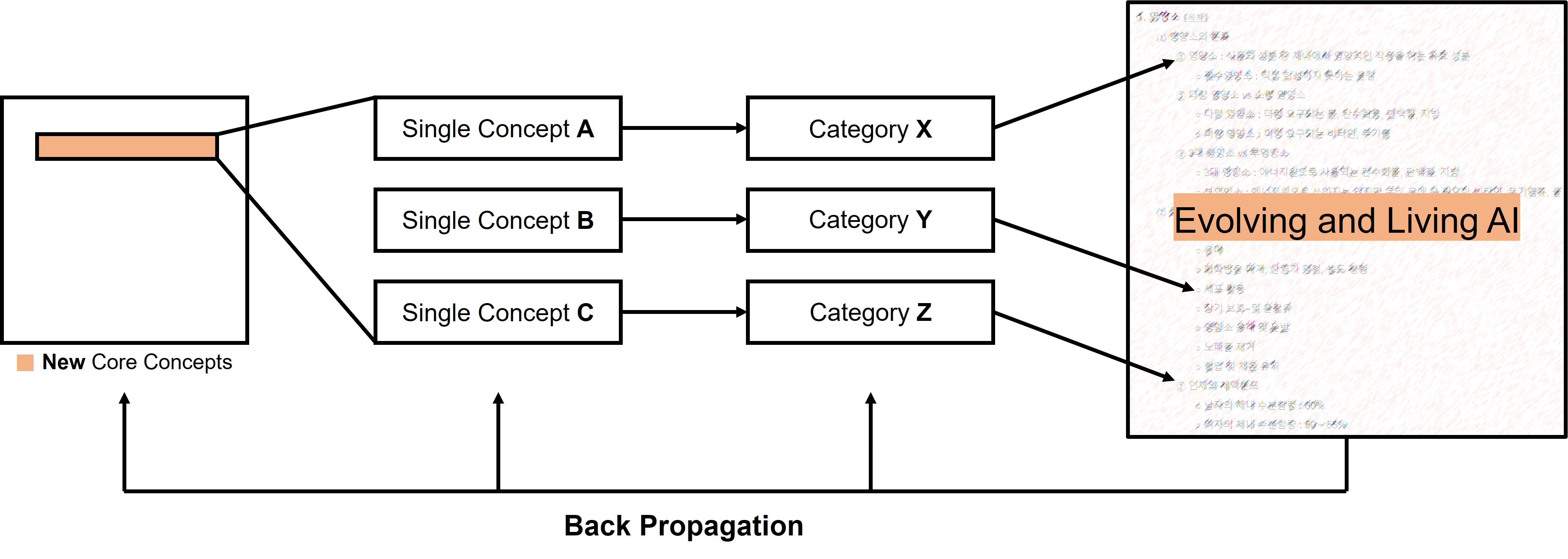
Figure. 5. 스스로 지식을 크롤링하는 모델 모식도
○ 방법 2. 크롤링을 통해 포스팅을 주기적으로 백업하는 아이디어 (링크) (complete)
○ 방법 3. 특정 포스팅이 새로 생성되거나 갱신되는 즉시 LLM 기반 인공지능 비서가 GitHub에 호스팅되는 외국어 플랫폼에 자동 반영되는 아이디어 (in progress) : 번역 프로젝트
○ 방법 4. 리뷰어 AI, 즉 크롤링 및 LLM을 이용해서 내용의 오류 및 오탈자를 검토하는 모델 (in progress)
○ ✅ 포스팅 첫 행에 "font-size: 14pt;"이 들어가는 모든 포스팅 찾기
○ ✅ 오탈자(e.g., 한글자모만 덜렁 있는 경우)가 있는 모든 포스팅 찾기
○ ✅ 참조되는 포스팅이 변경됨에 따라 변경이 필요한 모든 참조 하이퍼링크 찾기
○ ✅ 더 구체적인 파트를 링크해야 하는데 단순히 포스팅에 대한 하이퍼링크만 있는 모든 하이퍼링크 찾기
○ ✅ 코드 글에서 style에 white-space: pre가 없는 경우를 찾기
○ ✅ 한글 티스토리 ↔︎ 영문 깃허브 미스매치 포인트 찾기
○ ✅ ChatGPT API 혹은 LLaMa2로 내용의 오류를 주기적으로 지적해주는 모델
○ ✅ 이미지 및 첨부파일 모두 다운로드
○ ✅ '[목차]'가 볼드체로 돼 있는 모든 포스팅 찾기
○✅ 불필요한 <footnote> ... </footnote> 찾기
○ 방법 5. 전체 포스팅 관리 DB : ID, 제목, 내용, 댓글, 링크, 백링크, 최근 수정 여부 → LLM 기반으로 포스팅 간 연결 관계를 헤아려 현 블로그의 지식 체계에 대한 hierarchy를 확보할 수 있음 (ref) (in progress)
○ 방법 6. LLM으로 파일들, 서버, 또는 DB를 관리해 주는 인공지능 비서 (not started) : 추후에 LLM은 이런 인공지능 비서 관련 프로젝트로 발전할 것으로 전망
2-4. 크라우드 소싱 (in progress) : SNS, NLP
○ 개인이 힘을 얻을 수 있는 또다른 방법인 크라우드 소싱을 컨텐츠 획득에 도입하는 방법을 기술합니다.
○ 방법 1. 사용자 행동 정보 (complete) : 마이크로소프트의 Clarity로 동영상 및 열지도 형태로 다음을 구현할 수 있음

Figure. 6. Clarity로 만든 사용자 행동 열지도
○ 주어진 포스팅에서 어떤 부분이 중요한지 사용자의 집단지성을 통해 알 수 있음 → 요약글 생성 가능
○ 국가별로 어떤 글이 인기가 있는지 알 수 있음
○ 의도한 interactive web function을 잘 사용하는지 알 수 있음
○ 체류 시간 등 사용자 행동이 활발한 글이 무엇인지 알 수 있음
○ Javascript error가 어디에서 일어나는지 알 수 있음
○ 개별 사용자 추적
○ 실시간 사용자 파악
○ 방법 2. 이 블로그의 Q&A
○ 이미 많은 독자분들께서 유용한 질문, 자료를 제공해 주셨습니다. 하지만, 대체로 질문을 통해서 저와 질문자 모두 많은 정보를 교류할 수 있다는 것을 알 수 있습니다. 1) 어른이 되면서 주변에 무언가를 물어보기 어렵다는 점, 2) (네이버 지식in과 대비하여) 답변자가 빠른 시일 내에 답변할 수 있는 상태인지 모른다는 점이 기존 Q&A와 대비되는 점입니다.
○ 방법 3. Chatbot (complete)
○ 앞서, core concept를 모아놓은 지식의 집대성에 대한 구상을 밝혔는데, 이는 1) core concept는 적은 비율로 존재하므로 인간의 노력으로 하나하나 모으는 게 가능하고, 2) 핵심 지식은 통찰력과 관련 있어서 인공지능이 접근하기에 너무 추상적이라 어려운 영역이기 때문입니다. 하지만, LLM은 일단 core concept를 정의해주면 모든 디테일을 알려줄 수 있어서, LLM과 core concept 집대성의 결과는 인류의 모든 지식의 청사진을 그릴 수 있는 가능성을 제시할 수 있습니다.
○ 현재 OpenAI의 ChatGPT Store를 통해 챗봇을 구현해 두었습니다. (app, ref, YouTube)
○ Meta의 LLaMa, LLaMa2, mistral 등 설치형 LLM을 이용하여 챗봇을 구현해 보기도 하였습니다. (ollama)
○ 방법 4. 컨텐츠 적극 홍보 : Twitter, 티스토리 포럼, 유튜브, 네이버 지식인 등
4. 구상 3. 이미지 생성 관련 (in progress) [목차]
3-1. 3D Images as Contents (not started)
○ 이 블로그에 게시된 일부 이미지는 3D 이미지로 재탄생할 겁니다. AI 알고리즘을 통해 여러 장의 2D 이미지를 통해 3D 이미지를 재탄생시키는 것이 비로소 가능해진 시대가 왔습니다.

Figure. 7. Building Rome in a Day

Figure. 8. NeRF

Figure. 9. Michelangelo
3-2. 저작권 분쟁 해소 (complete)
○ 또한 기존의 이미지를 원하는 스타일에 재구성하는 게 가능해진 시대가 도래했습니다. 이를 통해 보다 적재적소한 이미지를 게시함과 동시에 저작권과 관련된 분쟁 소지를 상당 부분 해소할 것이라고 기대하고 있습니다.

Figure. 10. Google Style Transfer
○ 현재 생성형 모델 중 DALL∙E가 가장 성공적이므로 이를 적극적으로 활용하고자 합니다. 심지어 주어진 포스팅 내용에 맞는 이미지를 적절하게 생성할 수 있어 이 블로그와 상당한 시너지가 예상됩니다. 다만, 아직 이미지 내 글자들에 오탈자가 많이 발견되고 있어 이 부분은 불완전해 보입니다.

Figure. 11. DALL∙E가 이해한 저작권 우회 전략
3-3. 이미지 복원 (not started)
○ 위와 같은 논의를 더 연장한다면, 저작권을 떠나 일부 이미지의 경우 그 퀄리티가 꽤 좋음에도 워터마크나 불필요한 문자들이 덧쓰여 있어서 곤란한 상황이 있을 수도 있습니다. 이 경우 DIP(deep image prior)를 활용한다면 우리가 원하는 부분을 복원하는 것도 가능할 것입니다.

Figure. 12. DIP를 활용한 inpainting
3-4. 이미지 워터마크 개발을 통한 저작권 우회 전략 (not started)
○ 저작권법 제102조 제4호에 따르면 "정보검색도구를 통하여 정보통신망 저작물 등의 위치를 알 수 있게 하는 행위"는 저작권 침해로 보지 않습니다. 이에 구글, 네이버 등의 서치엔진 플랫폼은 저작권 침해로부터 자유롭게 이미지 등을 표시할 수 있게 됩니다. 이미지의 원문 링크를 표시하고 이미지를 다운로드 받으면 자동으로 워터마크를 새기는 기술을 개발한다면 블로그에 이미지를 업로드하는 행위가 저작권법으로부터 자유로워질 수 있습니다.
5. 구상 4. 번역 프로젝트 (complete) [목차]
○ 개요
○ 목적 1. 외국인 유입자 확대 : 한국어 사용자 전세계 7,000만. 전세계 인구 70억. 100배의 이득을 모두 확보하기 위해서는 번역 프로젝트가 필수적일 것으로 보입니다. Real-time으로 특정 언어의 게시글이 수정되면 다른 언어 전부가 수정되는 프로젝트를 구상하고 있습니다.
○ 목적 2. 티스토리 의존성 감소 : 최근 일방적인 티스토리 정책을 보면서 생각이 많아지고 있습니다.
○ 목적 3. 기술적 우위를 통한 차별성 강조 : LLM을 도입하는 등 기술적 차별화를 꾀하여 필자의 역량을 강화하고 독자들의 만족도를 개선
○ 중국어 번역 웹사이트 (바이두 개설 완료)
○ 방법 1. 네이버 파파고 이용 (기각)
【티스토리】 티스토리에 네이버 파파고 링크 연결하기
티스토리에 네이버 파파고 링크 연결하기 추천글 : 단계 1. 블로그 관리 → 꾸미기 → 스킨 편집 → html 편집 → HTML 단계 2. 다음과 같은 코드가 있는 부분을 찾음 수정 삭제 단계 3. 그 코드 위에
nate9389.tistory.com
○ 『html 파싱 → 전처리 → 네이버 파파고 연동 → 후처리 → 번역문 간단 교정』 등의 5단계 절차를 통해 진행하였습니다.
○ 단점 : 품이 많이 듦
○ 방법 2. 구글 번역 API, 크롤링 (기각)
○ 단점 : 쓰기 어렵고 번역 퀄리티가 너무 낮음
○ 방법 3. Python 크롤링 → 마크다운 변환 → ChatGPT API → GitHub commit (완료) (ref)
○ Python 크롤링 : 파이썬 requests 라이브러리 사용
○ 마크다운 변환 : BeautifulSoup 라이브러리 사용
○ ChatGPT API : instruction이 길어지면 번역 품질이 매우 크게 떨어지는 문제가 있어 텍스트 전처리가 필요함
○ 방법 4. Python 크롤링 → 마크다운 변환 → LLaMa2 API → GitHub commit (진행중)
○ 장점 : 설치형이므로 무료이고 재현 가능성이 있음. 더 효율적인 fine-tuning이 가능. ollama를 쓰면 쓰기 쉬움
○ 비고 : Meta의 API를 사용하면 LLaMa2도 돈이 발생함 (Replicate)
○ 정책 1. 너무 완벽한 번역글은 생성하지 않도록 함
○ 이유 1. 너무 완벽한 번역시스템은 국내 지식재산이 해외로 유출되는 것을 촉진하기 때문
○ 이유 2. 원본 사이트에 많은 에너지를 들이는 데 반해, 원본 한글 사이트의 유입 자체를 떨어트릴 수 있기 때문
○ 정책 2. 원본 사이트에서 수정을 하는 것만으로 다른 외국어 사이트 전부가 일체 변경되는 시스템을 구상함
○ 다른 외국어 사이트 : GitHub로 개설 혹은 개설 예정. 영어, 일본어, 스페인어 등
○ 1단계. 원본 사이트(e.g., 티스토리)에서 수정
○ 2단계. javascript에서 수정 이벤트를 인식하여 LLaMa2 기반 인공지능 비서에게 전달
○ 3단계. LLaMa2 기반 인공지능 비서는 내부 시스템에 명령어를 입력하여 Git Clone 및 Git Commit을 실행
○ 4단계. 다른 GitHub 외국어 사이트가 일체 변경
6. 구상 5. 출판 프로젝트 (complete) [목차]
○ 목적 1. 교육시장의 성장
현재 시장 상황이 예사롭지 않습니다. 동남아, 인도 등의 지역은 젊은 인구가 많지만 교육수준은 많이 부족한 상황입니다. 이들 지역에서 교육 수요는 폭발적으로 증가하고 있으며, 10년 뒤에는 정말 주목할 만한 시장이 될 것 같습니다. 그리고 아프리카. 아직은 저평가됐지만 30 ~ 50년 뒤의 교육 시장이 주목됩니다. 국내 교육 시장에는 학령 인구 부족 등에 따른 악재가 많다는 것은 이미 많이 알려져 있는 사실이고, 결국은 해외로 시선을 돌리는 게 맞는 방향일 텐데요. 그럼에도 시장 상황을 살펴 보기 위한 수단이 턱없이 부족합니다. 그래서 저는 해외 교육 시장의 분위기를 헤아리기 위한 지표 상품으로서 도서 출판을 채택하였습니다.
○ 목적 2. 출판의 가능성 재발견
이력서(curriculum vitae, CV)에서 'Honor'로 쓰여지는 부분이 있습니다. 말 그대로 명예로운 실적을 쓰는 부분인데요. 그러한 예시를 나열하자면, 어학, GPA, 봉사활동, 교환학생, 대회수상 등이 있을 텐데 그 중에서도 가장 강력한 것은 논문과 특허입니다. 논문을 쓰기 위해서는 아카데미쪽을 꽉 잡고 계시는 교수님들 밑에서 일정 요건을 달성해야 하며, 특허를 쓰기 위해서는 특허에 대한 지식, 발명의 완성, 상당한 비용을 요합니다. 논문, 특허와 동등한 지위에 있는 제3의 명예가 있는데, 그게 바로 출판입니다. 생각보다 많은 분들이 모르고 있는 부분이라고 생각합니다. 앞으로 종이시장은 쇠하고 전자출판 시장은 흥할 것입니다. 전자출판 시장의 무궁무진한 성장 가능성과 쉽게 전자출판을 통해 누구든지 출판을 할 수 있다는 사실에 놀라울 따름입니다.
○ 전략 1. 페스트북 미디어(https://festbook.co.kr/)와의 제휴
저는 교육시장의 성장과 출판의 가능성을 재발견함으로써 전자출판 제휴 업체를 모색하였고, 페스트북 미디어를 통해 출판을 진행했습니다. 독점계약은 아니지만 좋은 조건이라고 판단하여 다수 (~100권) 출판계약을 맺으리라 기대하고 있습니다.
○ 전략 2. 출판사의 설립
○ AI 및 플랫폼의 시대에서 작가들의 기회 확대 및 역량 강화를 위해 출판사 설립을 계획하고 있습니다.
○ 출판사 이즈그리민 공동 설립 (23.06.27)
○ 출판 예시
7. 구상 6. Apps on a Blog (in progress) [목차]
6-1. 보팅 시스템 (not started)
○ 저의 호기심은 사회통계학적인 현상에도 닿아 있습니다. 그것을 알기 위해서는 문헌으로는 한계가 있습니다. 그렇기에 퀵툴바나 팝업창을 활성화시켜서 설문조사를 진행시킬 생각입니다. 추가로 보팅 시스템이랑 관련인 크게 없는 얘긴데요. 메칼프의 법칙에 따르면 네트워크는 그 제곱에 비례하는 가치를 가진다고 합니다. 그 이론을 유튜브나 사이트에도 적용할 수 있지 않을까 생각합니다. 그걸 확인해 보고 싶습니다.
6-2. 지식의 정렬 (not started)
○ 위키백과는 리스트이지만 지식은 트리로 정렬돼야 한다. 모든 지식에 순서를 부여한다면? 뒤에 나오는 지식은 앞에 있는 지식들로만 설명할 수 있는 것입니다. 그런 식이라면 모든 지식에 순서를 부여할 수 있고 새로운 지식이 올 때 그 지식이 몇 번째인지를 판별하는 인공지능을 만들 수 있겠죠. 그 지식은 자동으로 적재적소한 곳에 배치될 것이고, 이로써 기계가 새로운 지식을 이해했다고 말할 수 있지 않을까요. "A는 B와 C로 구성돼 있다."라는 문장이 있으면 A, B, C 중 가장 나중에 나오는 것의 순서 바로 다음에 그 문장을 배치시키면 될 것 같습니다.
○ 이 작업에 거대 언어 모델(LLM)을 사용할 수 없을까?
6-3. 자동으로 서식을 정리하는 것 (complete)
○ Python BeautifulSoup 라이브러리가 해당 작업을 효율적으로 처리할 수 있습니다.
○ ChatGPT로 html 코드 내 한국어를 번역할 적에 html 코드도 trimming 되는 것을 확인하였습니다.
6-4. 자동으로 글을 생성하는 것 (complete)
○ 파이썬으로 html 형식의 글을 자동 생성할 수 있습니다. (ref) 저는 이를 실제 생물정보학 업무에 사용하고 있습니다.
○ 이 블로그에서는 주식 추이, 여론 동향, 기상 현황 등을 분석할 때 사용하고자 합니다.
6-5. 이미지 in-link (not started)
○ 예시
EGF/EGFR Signaling Pathway - Creative Diagnostics
Figure 1. EGF/EGFR Signaling Pathway. EGF/EGFR overview EGFR(Epidermal growth factor receptor), or ErbB1/human epidermal growth factor receptor (HER)-1, is a transmembrane protein which is the receptor of the ligands from EGF family. EGFR is a 170-kDa glyc
www.creative-diagnostics.com
6-6. Simple Apps on a Blog (in progress)
○ 우선 간단한 앱부터 블로그에 설치할 계획입니다.
✓ 여러 종류의 변환기 : USD ↔︎ KRW, 10진수 ↔︎ 16진수, 시간대 변환, meter ↔︎ feet, kg ↔︎ pound, 섭씨 ↔︎ 화씨
✗ 타로카드 셔플을 자동으로 해주는 프로그램 (예정)
✗ 웹 기반 MBTI 테스트 (예정)
✗ 역사를 4차원 지도로 설명해주는 프로그램 (예정)
✗ 특허의 시기적 요건을 계산해주는 프로그램 (예정)
✗ 툴바를 통해 LLM (e.g., ChatGPT) 모델을 사용할 수 있는 UI (예정)
✗ 성형수술 시뮬레이터 (예정)
✗ 자유게시판 (예정)
✗ 스도쿠 문제 생성 (예정)
6-7. Database on a Blog (not started)
○ 방법 1. 데이터셋을 NAS에 설치한 뒤 블로그에 해당 url을 넘기는 방식이면 전혀 어렵지 않음
○ 방법 2. GitHub를 진지하게 고민하고 있음
○ 하지만 어떤 데이터셋을 공유할지가 문제가 됨
○ 현재로서는 TCGA, GEO 등의 생물정보학 데이터셋을 중점에 두고 있음 : UCSC Xena가 좋은 예시
UCSC Xena
Warning: It appears as though you do not have javascript enabled. The UCSC Xena browser relies heavily on JavaScript and will not function without it enabled. Thank you for your understanding.
xenabrowser.net
6-8. 인류 지식의 청사진을 tSNE로 나타내는 방식 (complete)
○ 방향 1. https://artsexperiments.withgoogle.com/tsnemap/
Google Arts & Culture Experiments - t-SNE Map Experiment
What if art was a land you could walk in? Explore a 3D interactive map of artworks shaped by machine learning with Google Arts & Cutlure
artsexperiments.withgoogle.com
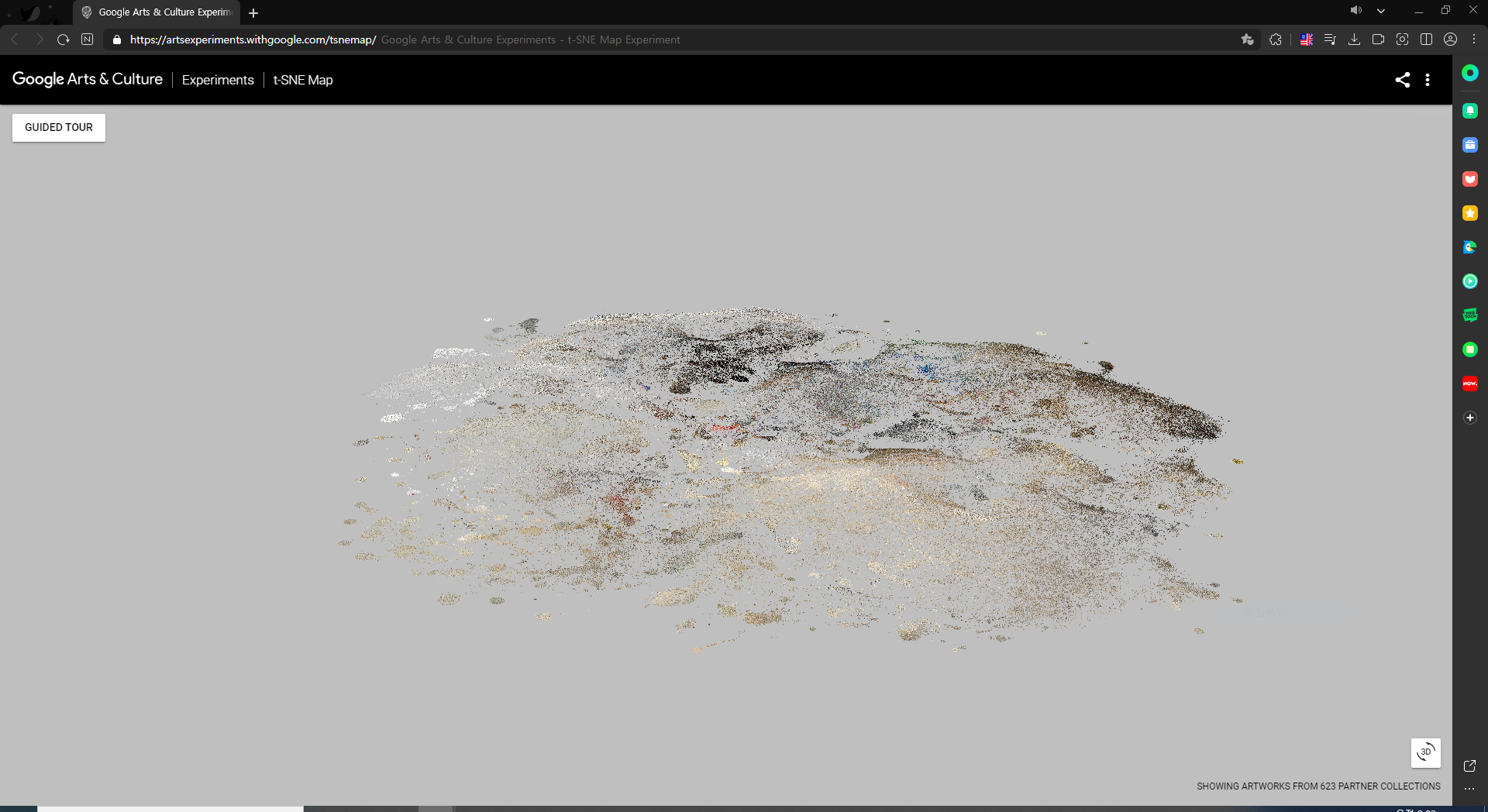
Figure. 13. 지식의 청사진을 tSNE로 나타낸 그림
○ 방향 2. 언어 모델(e.g., PubMedBERT)로 논문들을 tSNE로 나타낸 그림
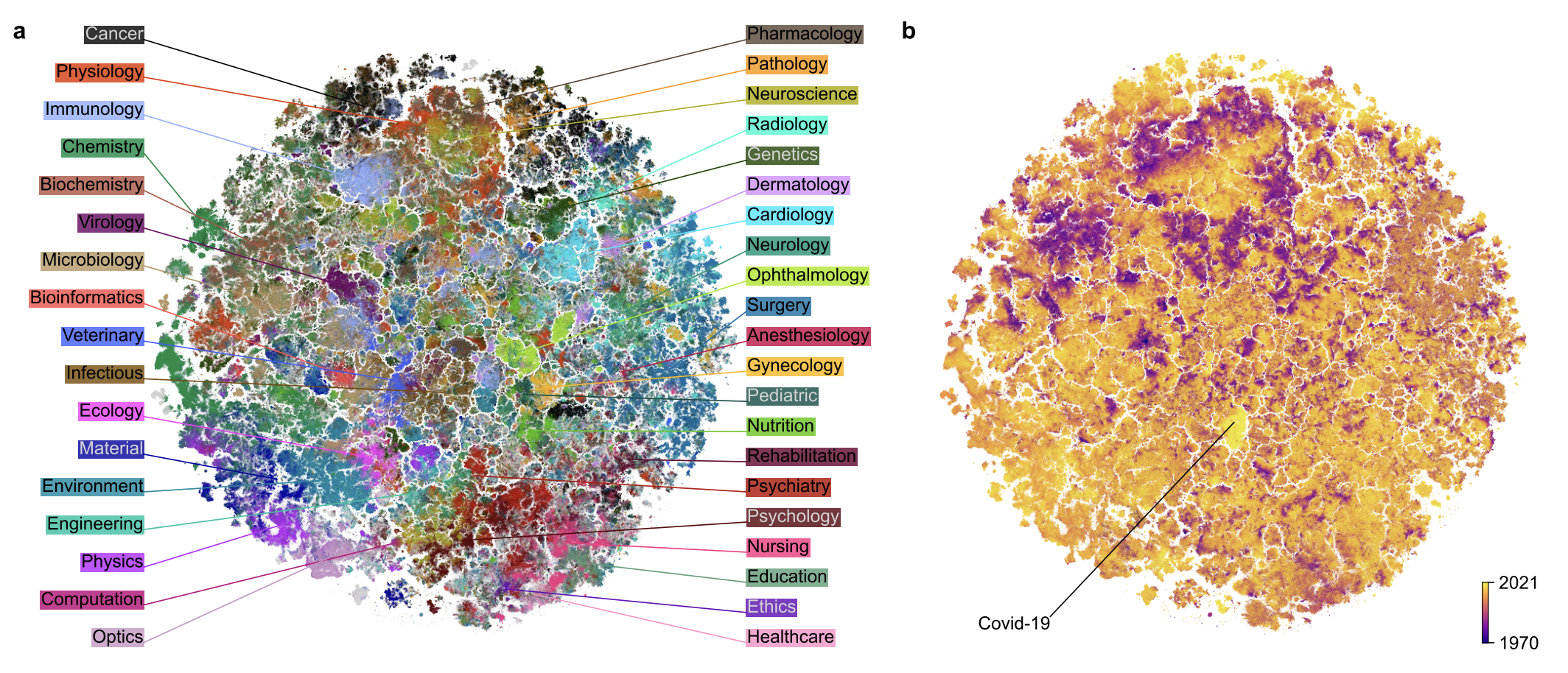
Figure. 14. The landscape of biomedical research
○ sentence embedder를 이용한 티스토리 포스팅 임베딩
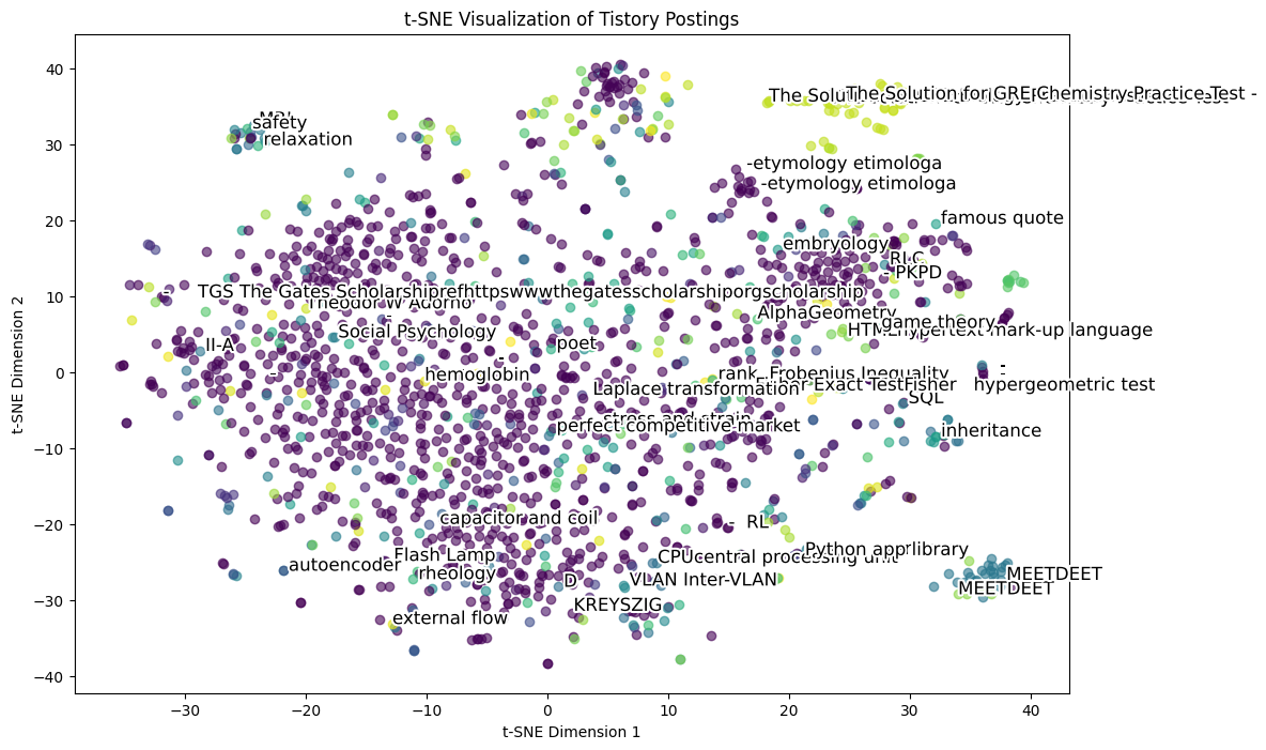
Figure. 15. all-MiniLM-L6-v2를 활용한 포스팅들의 2차원 시각화
8. 구상 7. 휴먼-컴퓨터 인터페이스 (HCI) (not started) [목차]
7-1. 지식의 습득
○ 모든 지식을 정리할 수 있다면? VR 장치를 실용화할 수 있다면? 뇌파를 딥러닝으로 분석할 수 있다면? 모자 쓰듯이 머리에 쓰는 것만으로 지식을 습득하는 장치를 만들 수 있을 것이다.
7-2. 지식의 생성
○ 위 논의를 확장하면 머리에 쓰는 것만으로 그 사람의 지식체계를 확보하는 장치도 만들 수 있을 것이다. 그러면 인간의 불멸화 내지 인간의 전산화를 실현할 수 있지 않을까?
7-3. 사람 인격의 재구성
○ 검색 엔진이나 모든 것의 백과사전이 있어서 특정 개인이 열람하는 컨텐츠들을 추적하면 그 사람의 머릿속 스키마를 구현할 수 있지 않을까? (실험 결과)
7-4. 시공간 오믹스
○ 시공간 오믹스를 구현한다면 data-interpreting foundational model로 해석하게 하여 human-to-computer를 만들 수 있을 것
9. 구상 8. 지식의 본질에 대한 연구 (in progress) [목차]
10. 끝맺음 [목차]
지식의 바벨탑을 쌓고 싶습니다.
이 세상의 정상에 올라 그곳에서 당신을 기다리겠습니다.
입력: 2019.11.01. 20:52
수정: 2024.12.30 00:14