21강. 자연어 처리(NLP)와 거대 언어 모델(LLM)
추천글 : 【알고리즘】 알고리즘 목차
1. 자연어 처리 [본문]
2. 거대 언어 모델 [본문]
3. 생물정보학과 언어 모델 [본문]
a. 프롬프트 엔지니어링
c. LLM 관련 탐구 주제
1. 자연어 처리(natural language processing, NLP) [목차]
⑴ 정의 : 텍스트 기반의 인공지능 모델
⑵ 텍스트 전처리 : 비정형 텍스트를 컴퓨터가 인식하게 하기 위해 수행하는 전처리
① 토큰화(tokenization)
○ 문장 혹은 말뭉치(corpus)에서 최소 의미 단위인 토큰으로 분할하여 컴퓨터가 인식하도록 하는 방법
○ 영어 : 주로 띄어쓰기 기준으로 나눔
○ 75개의 영단어 ≃ 100개의 토큰
○ 예 : I / ate / noodle / very / deliciously
○ 한글 : 주로 단어 안의 형태소를 기준으로 나눔
○ 예 : 나 / 는 / 국수 / 를 / 매우 / 맛있게 / 먹었다
○ 예 : OpenAI Tokenizer
② 품사 태깅(POS tagigng, part of speech tagging)
○ 형태소의 품사를 태깅하는 기법
③ 표제어 추출(lemmatization)
○ 단어들로부터 표제어(사전어)를 찾는 기법
○ 예 : am, are, is → be
④ 어간 추출(stemming)
○ 단어에서 접두사 및 접미사를 제거하여 어간을 획득하는 기법
⑤ 불용어(stopword) 처리
○ 조사, 접미사 같은 실제 의미 분석을 하는 데 거의 기여하지 않는 단어를 처리하는 기법
⑶ 텍스트 마이닝(text mining)
① 토픽 모델링
○ 기계학습 및 자연어 처리 분야에서 토픽이라는 문서 집합의 추상적인 주제를 발견하기 위한 통계적 모델 중 하나
○ 텍스트 본문의 숨겨진 의미 구조를 발견하기 위해 사용됨
② 워드 클라우드
○ 자연어 처리를 통해 사람들의 관심사 또는 빈도수를 단순 카운트하여 시각화
③ 소셜 네트워크 분석(SNA, social network analysis)
○ 그룹에 속한 사람들 간의 네트워크 특성과 구조를 분석하고 시각화하는 분석 기법
④ TF-IDF(term frequency-inverse document frequency)
○ 여러 문서로 이루어진 문서 군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지 추출하는 기법
⑷ 자연어 처리 모델
① 종류 1. LSA(latent semantic analysis)
② 종류 2. PLSA(probabilistic latent semantic analysis)
③ 종류 3. LDA(latent dirichlet allocation) : 생성형 확률 모델. reference 없이 deconvolution을 할 때에도 사용할 수 있음 (ref)
④ 종류 4. Word2Vec : Skip-gram은 Word2Vec 모델의 한 구성 요소
⑸ 자연어 모델의 평가 (ref)
① parallel text dataset : Canadian Parliament (영어 ↔ 프랑스어), European Parliament (여러 언어 지원)
② SNS
③ Bleu score (ref)
④ perplexity
2. 거대 언어 모델(large language model, LLM) [목차]
⑴ 정의 : 파라미터의 수가 billion 단위인 자연어 처리 모델
① 파라미터의 수를 세는 방법은 다음을 참고
② 용어 1. 7B, 13B, 30B, 65B의 의미 : 자연어 모델을 구성하는 파라미터 개수가 7 billion, 13 billion, 30 billion, 및 65 billion이라는 것
③ 용어 2. token : 모델이 처리하는 텍스트의 단위
○ word-level tokenization : [ChatGPT, is, an, AI, language, model, .]
○ subword-level tokenization : [Chat, G, PT, is, an, AI, language, model, .]
○ character-level tokenization : [C, h, a, t, G, P, T, , i, s, , a, n, , A, I, , l, a, n, g, u, a, g, e, , m, o, d, e, l ]
④ 용어 3. 0-shot, 1-shot, 5-shot, 64-shot 등의 의미 : 하나의 task 당 주어지는 예시의 개수를 의미
○ 0-shot prompting
Q: <Question>?
A:
○ few-shot prompting
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A:
⑵ 트랜스포머(transformer)
① 단계 1. 트랜스포머 인코더(transformer encoder) : 입력 시퀀스를 받아서 이를 더 높은 수준의 표현으로 변환
○ 훈련 방식 : NSP, MLM
○ 다음 문장 예측(next sentence prediction; NSP) : 입력 데이터의 문장쌍 A, B를 구성하여, B가 A 다음 문장인지 여부 결정
○ 첫 번째 문장 : "The quick brown fox jumps over the lazy dog."
○ 두 번째 문장 : "The dog is not amused."
○ 예측 결과 : 두 번째 문장이 첫 번째 문장의 다음 문장인지 여부 (예 : "No")
○ 마스킹된 언어 모델링(masked language modeling; MLM) : 문장의 일부 단어를 마스킹하고, 마스킹된 단어를 예측
○ BERT 등의 트랜스포머에서 인코더를 트레이닝시킴
○ 1-1. 자기 주의 메커니즘(self-attention mechanism)
○ 1-1-1. 문장을 여러 개의 토큰으로 분리
○ 1-1-2. 입력된 시퀀스에서 각 토큰의 쌍에 대해 "query", "key", "value"를 생성하여, 각 토큰이 다른 토큰에 얼마나 주의를 기울일지(attention score)를 계산

Figure. 1. 토큰쌍의 attention score
○ 1-1-3. positional encoding : 트랜스포머는 입력된 단어의 순서를 직접 알 수 없어서, 각 단어의 위치 정보를 positional encoding으로 추가. 이를 통해 모델이 시퀀스 내의 순서 정보를 이해할 수 있음. 예를 들어, sin, cos 함수로 정의되는 경우 가까울수록 내적값이 커져서 인접 관계를 이해할 수 있음
○ 1-1-4. 인코더 내의 각 토큰(단어)은 다른 모든 토큰들과의 관계를 학습
○ 1-1-5. 토큰 임베딩(token embedding) : attention score를 기반으로 각 토큰의 가중합을 계산하여 각 토큰을 새로운 표현으로 변환. positional encoding으로 임베딩된 결과를 positional embedding이라고 함
○ 1-1-6. attention head가 여러 개인 경우를 multi-head attention이라고 함
○ 1-2. FFN(feed-forward neural network) : self-attention을 통해 생성된 표현을 더욱 정교하게 변환
○ 각 토큰 임베딩을 개별적으로 튜닝하고 이때 비선형 활성화 함수가 사용됨
○ 1-3. Add&Norm (LayerNorm) : self-attention과 FFN 뒤에 붙어 layer normalization을 수행
○ 1-4. "self-attention → Add&Norm → FFN → Add&Norm"과 같은 구조가 여러 레이어로 반복됨
○ 이를 통해 각 토큰 임베딩을 점점 더 문맥화된 벡터로 변환
○ 유형 1. 초기 레이어
○ 각 레이어의 여러 attention head들이 입력 피처에서 집중하는 부분에 편차가 큰 단계
○ 이 단계에서는 폭넓은 탐색을 통해 중요한 정보와 그렇지 않은 정보를 구분함
○ 유형 2. 중간 레이어
○ 각 레이어의 여러 attention head들이 일관되게 랭크가 낮은 정보에 집중하는 단계
○ 데이터에 내재된 노이즈를 식별하고 세부 사항을 이해함
○ 유형 3. 최종 레이어
○ 각 레이어의 여러 attention head들이 일관되게 랭크가 높은 정보에 집중하는 단계
○ 이를 통해 결정적인 정보를 추출하고 최종 결정을 내리는데 기여함
○ 1-5. sentence embedding : 최종적으로 각 토큰 임베딩을 종합하여 문장의 전체 의미를 나타내는 하나의 벡터로 변환. 트랜스포머 디코더는 트랜스포머 인코더가 만든 sentence embedding을 입력받는 게 아님. 트랜스포머 디코더는 인코더의 문맥화된 토큰 임베딩을 입력으로 받음
② 단계 2. 트랜스포머 디코더(transformer decoder) : 인코더에서 생성한 표현을 받아서 최종적으로 원하는 출력을 생성
○ 훈련 방식 : NWP

Figure. 2. 트랜스포머 디코더 문제 정의
○ 다음 단어 예측(next word prediction; NWP) : 주어진 문맥 내에서 다음 단어를 예측하는 작업
○ GPT 등의 트랜스포머에서 디코더를 트레이닝시킴
○ 2-1. 마스크된 자기 주의 메커니즘(masked self-attention mechanism)
○ 2-1-1. 디코더는 인코더에서 생성된 토큰 임베딩을 참고
○ 2-1-2. 디코더 내의 각 토큰은 이전 토큰들만을 참고하여 다음 토큰을 예측 : 모델이 미래의 정보를 보지 않도록 하기 위해 마스크 적용. 아래 그림에서 각 토큰들이 벡터 표현으로 임베딩됐음을 알 수 있음
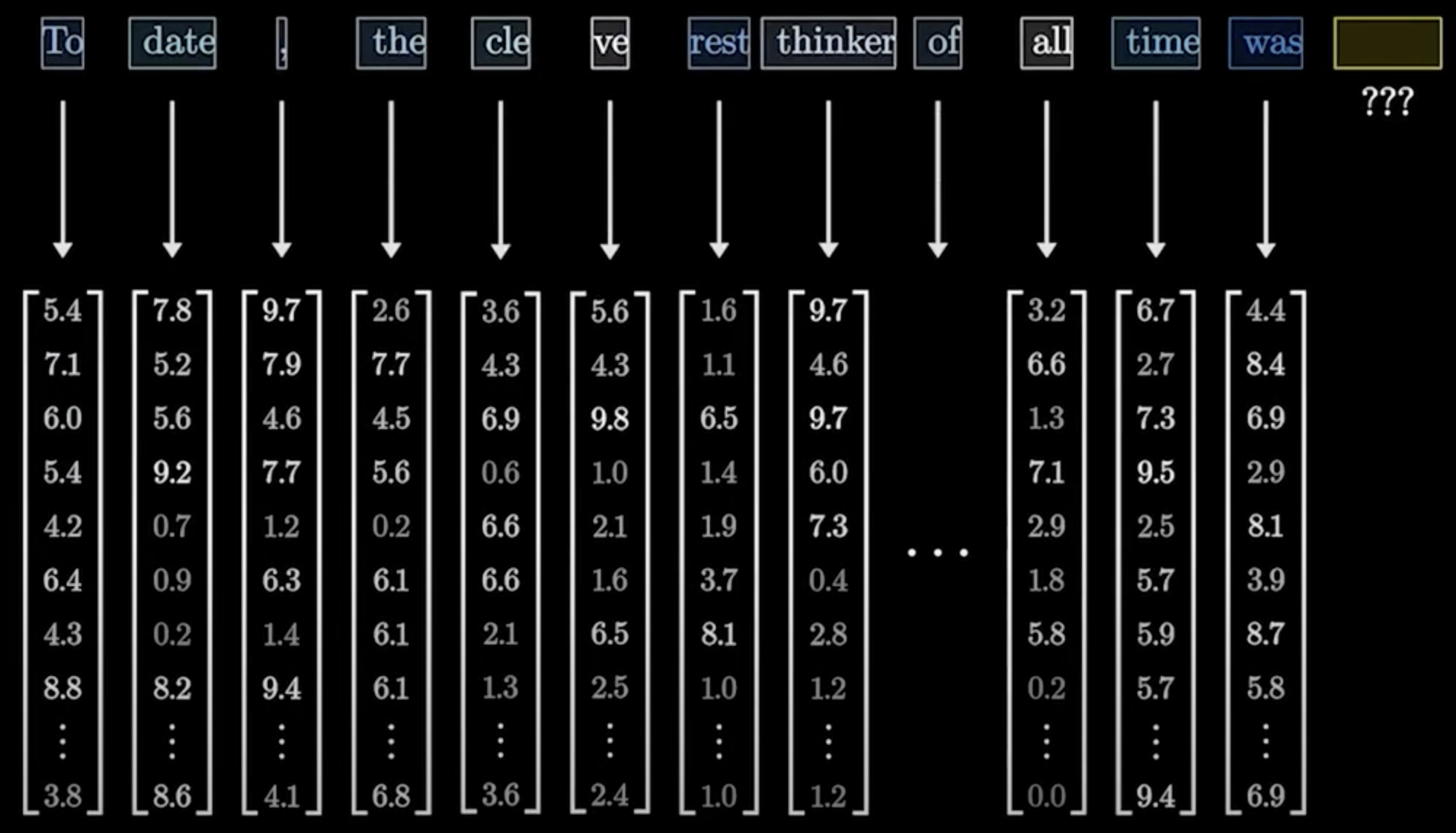
Figure. 3. 토큰 임베딩 결과와 다음 단어 예측 상황
○ 2-2. FFN(feed-forward neural network)
○ 디코더에서 생성된 표현을 더 정교하게 변환하여 최종 출력을 생성하는 데 사용
○ 인코더와 마찬가지로, FFN은 각 토큰 임베딩을 비선형적으로 변환
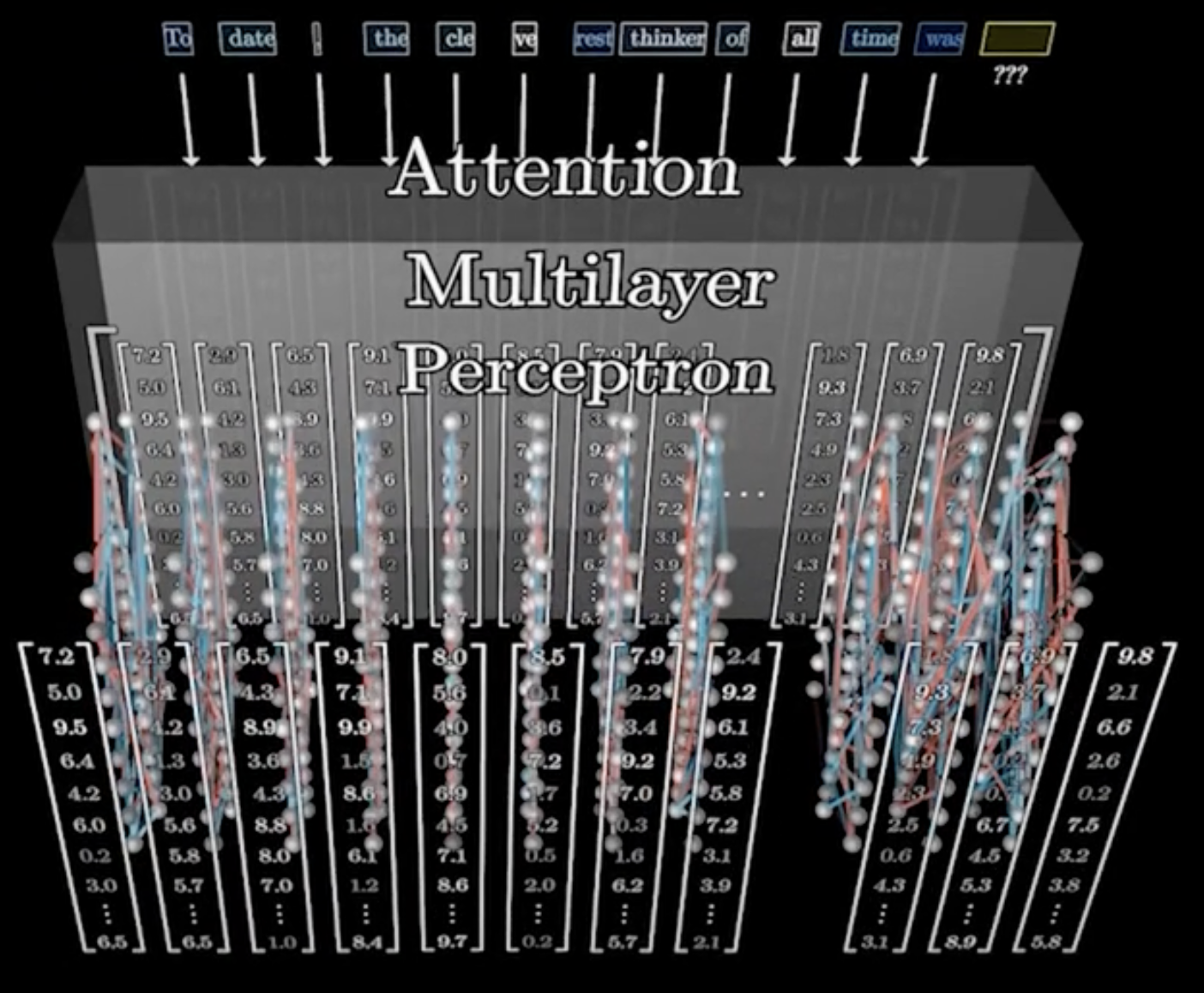
Figure. 4. attention multilayer perceptron
○ 2-3. 다중 디코더(multilayer decoder) : 여러 개의 디코더 레이어가 쌓여서 최종적으로 출력 시퀀스를 생성
○ attention multilayer percentron을 serial 하게 붙임으로써 계속 문장을 생성할 수 있음
○ 디코더는 인코더의 정보와 현재 생성 중인 시퀀스 정보를 결합하여 새로운 토큰을 예측
○ To date, the cleverest thinker of all time was ___ → undoubtedly
○ To date, the cleverest thinker of all time was undoubtedly ___ → Einstein
○ To date, the cleverest thinker of all time was undoubtedly Einstein, ___ → for
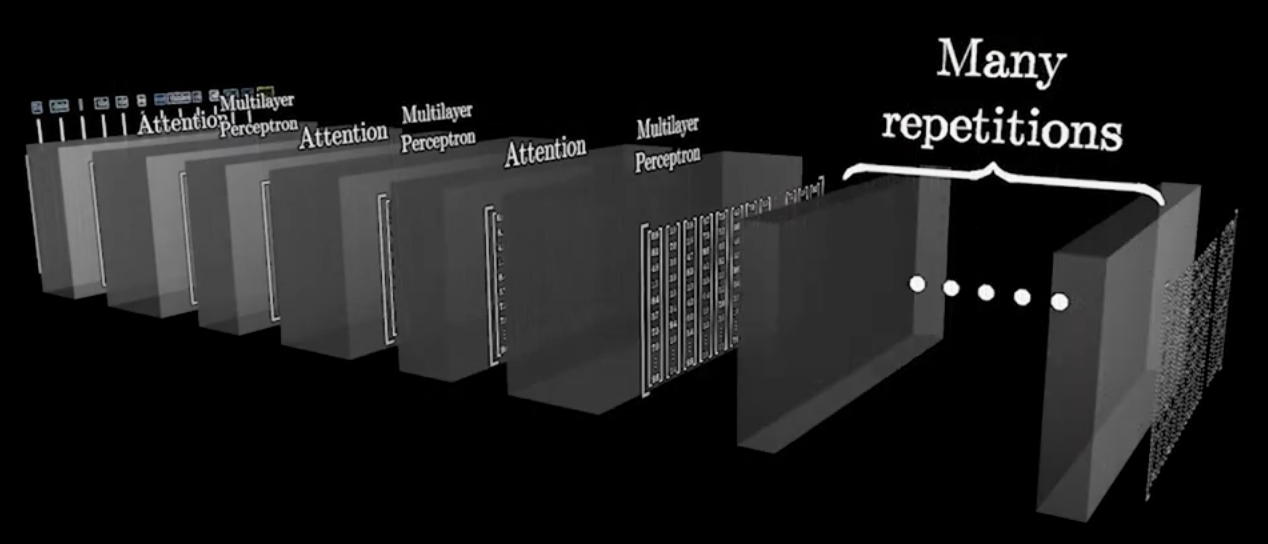
Figure. 5. 다중 디코더
⑶ 주요 파라미터
① temperature = 0 : 매우 결정론적 출력을 생성
② max_tokens API Call settings = 100 : 100 토큰까지의 응답이 capped
③ top_p = 1.0 : 모든 가능한 토큰을 사용하여 응답을 생성
④ frequency_penalty = 0.0 : 자연스럽게 반복되는 토큰을 피하지 않음
⑤ presence_penalty = 0.0 : 토큰 재사용에 대한 벌칙이 적용되지 않음
⑷ 종류
○ 양방향 트랜스포머를 사용하여 입력 시퀀스의 좌우 문맥을 모두 고려하여 텍스트 이해에 유리함
○ BERT의 입력은 최대 512 토큰이지만, positional embedding을 확장하여 입력을 늘릴 수 있음 : 2n을 보통 최대 입력으로 함
○ BERT 혹은 BioBERT를 Hugging Face에서 불러와서 주어진 문장에 대한 attention matrix를 만드는 함수
import torch
from transformers import BertTokenizer, BertModel
import matplotlib.pyplot as plt
import seaborn as sns
# BERT 모델과 토크나이저 불러오기 (OPTION 1)
'''
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
'''
# BioBERT 모델과 토크나이저 불러오기 (OPTION 2)
model_name = 'dmis-lab/biobert-base-cased-v1.1'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
# 입력 문장
sentence = "Find diseases associated with glucose"
# 토큰화
inputs = tokenizer(sentence, return_tensors='pt')
# 모델을 통해 출력값과 attention 가중치 계산
outputs = model(**inputs)
attentions = outputs.attentions # 이 값이 각 층의 attention 가중치
# 첫 번째 층의 첫 번째 헤드의 attention 가중치 시각화
attention = attentions[0][0][0].detach().numpy()
# 토큰 리스트
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
# Attention 가중치 시각화
plt.figure(figsize=(10, 10))
sns.heatmap(attention, xticklabels=tokens, yticklabels=tokens, cmap='viridis')
plt.title('Attention Weights')
plt.show()
② GPT, GPT-2, GPT-3, GPT-J, GPT-Neo, GPT-3.5, GPT-4, GPT-4o, GPT-o1
○ 입력 시퀀스의 좌에서 우로 순차적으로 문맥을 고려하여 다음 단어 예측에 집중함
○ 자기 회귀 모델(autoregressive model)을 사용함
| BERT | GPT-4 | |
| 개발자 | Google AI | OpenAI |
| 입력 데이터 | 입력 시퀀스의 좌우 문맥을 모두 고려 | 입력 시퀀스의 좌에서 우로 순차적으로 고려 |
| 파라미터 | 1.5 B | 340 M (= 0.34 B) |
| 훈련 방식 | 트랜스포머 인코더 (MLM, NSP) | 트랜스포머 디코더 (NWP) |
| 훈련 데이터 | 3 TB | 45 TB |
| 주요 응용분야 | 텍스트 이해 | 텍스트 생성 |
Table. 1. BERT와 GPT의 비교
④ Gopher
⑥ Flan, PaLM, Flan-PaLM
⑦ OPT-IML
⑧ LLaMA, LLaMA2, LLaMA3 : 설치형 모델. Meta에서 개발
⑨ Alpaca
⑪ Gemma
○ multi-query attention
○ RoPE embedding
○ GeGLU activation
○ RMSNorm
⑫ Mistral
○ group-query attention
○ sliding window attention
○ rolling buffer cache
○ pre-fill and chunking
⑬ ollama : 다음 LLM들을 모두 지원
○ Llama2 (7B)
○ Mistral (7B)
○ Dolphin Phi (2.7B)
○ Phi-2 (2.7B)
○ Neural Chat (7B)
○ Starling (7B)
○ Code Llama (7B)
○ Llama2 Uncensored (7B)
○ Llama2 (13B)
○ Llama2 (70B)
○ Orca Mini (3B)
○ Vicuna (7B)
○ LLaVA (7B)
⑭ AlphaGeometry : symbolic deduction을 구현하여 IMO 수준의 기하 문제를 풀 수 있음
⑮ MiniLM (Miniature language model)
○ 임의의 가변 길이 자연어 문장을 그 의미를 고려하여 384차원으로 만드는 함수 (ref)
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
import numpy as np
from scipy.sparse import csr_matrix
import pandas as pd
from sklearn.neighbors import NearestNeighbors
import torch
from torch.utils.data import DataLoader, TensorDataset
from xgboost import XGBClassifier
def sentences_to_embedding(sentences):
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
db = embedding_function.embed_documents(sentences)
emb_res = np.asarray(db)
return emb_res
sentences = []
sentences.append("What is the meaning of: obsolete")
sentences.append("What is the meaning of: old-fashioned")
sentences.append("What is the meaning of: demagogue")
emb_res = sentences_to_embedding(sentences)
⑯ 기타 유용한 생성형 AI 툴
○ Scite
○ SciSpace / typeset.io
○ Elicit.com
○ Elicit AI
○ Research Rabbit
○ Gemini
○ Tabnine
○ CodiumAI
○ AWS Code Whisperer
○ Sourcegraph Cody
○ NotebookLM
3. 생물정보학과 언어 모델 [목차]
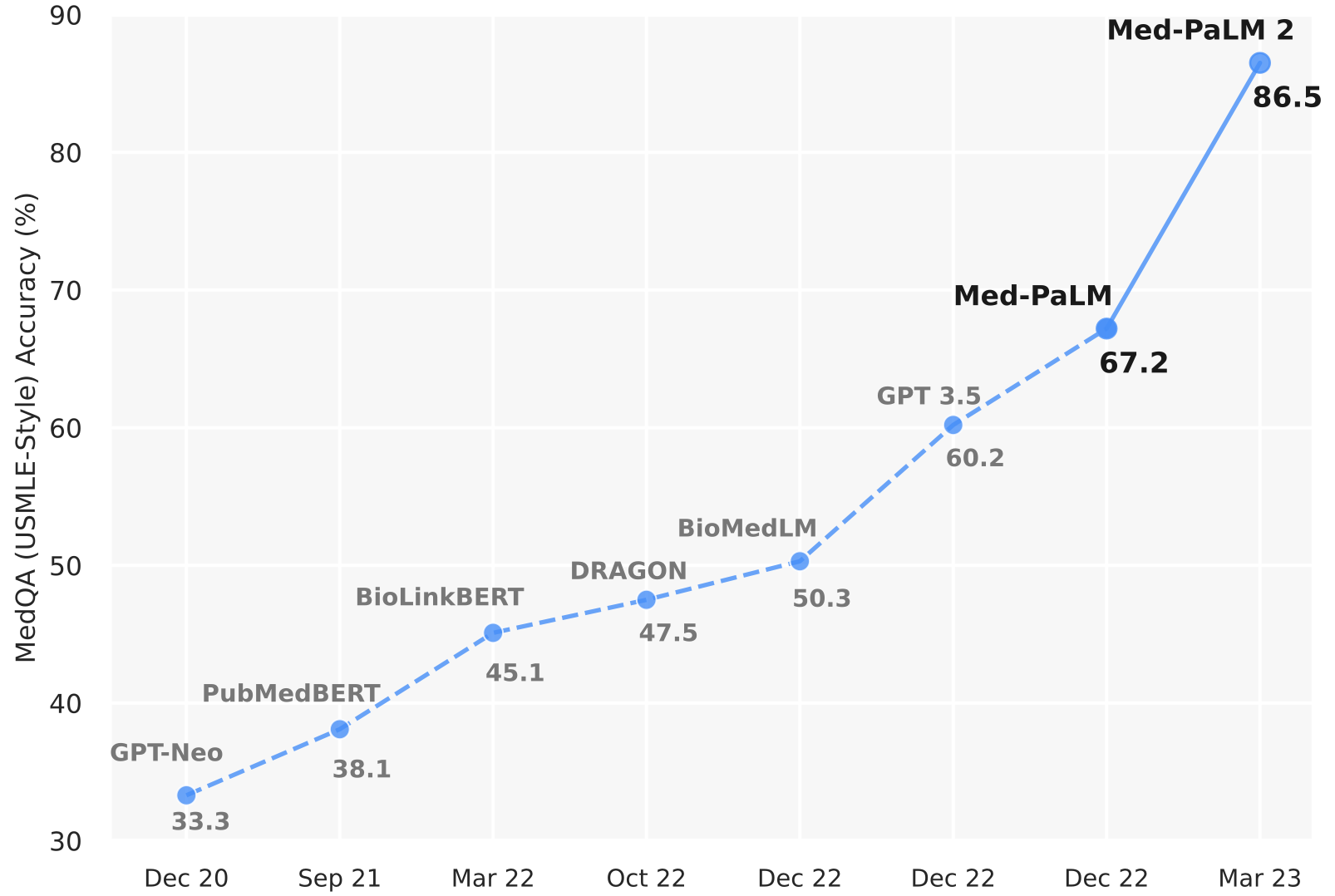
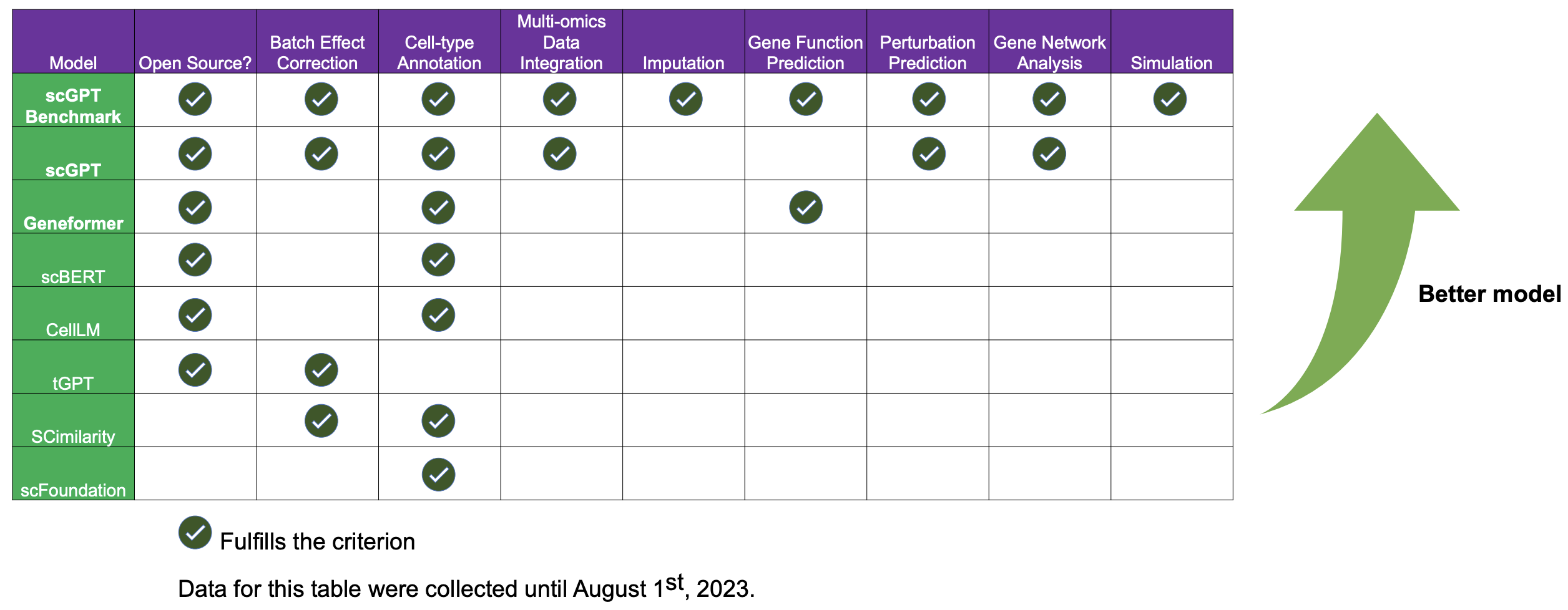
Figure. 6. 생물정보학과 언어 모델
⑴ BioBERT
⑵ BioNER
⑶ SQuAD
⑷ BioASQ
⑸ PubMedGPT (BioMedLM)
⑹ BioGPT
⑺ scBERT, scFormer : BERT 기반
⑻ GPT-Neo
⑼ PubMedBERT
⑽ BioLinkBERT
⑾ DRAGON
⑿ BioMedLM
⒀ Med-PaLM, Med-PaLM M, Med-Gemini
⒂ tGPT
⒃ CellLM
⒄ Geneformer : BERT 기반. 트랜스포머 인코더 기반의 아키텍처 사용. pretraining → finetuning과 같이 사용. zero-shot 기능이 사실상 무용지물
⒅ scGPT : GPT 기반. 트랜스포머 디코더 기반의 아키텍처 사용. pretraining → finetuning과 같이 사용. pretraining model의 zero-shot 퍼포먼스도 상당히 우수함
⒇ CellPLM
⒇ Evo2 : 8.8 trillion nucleotides에 달하는 거의 모든 생물의 DNA를 모아서 만든 alignment-free foundation model
⒇ GenePT
⒇ Concerto
⒇ scTrans
입력: 2021.12.11 17:34
수정: 2024.09.13 15:30
'▶ 자연과학 > ▷ 알고리즘·머신러닝' 카테고리의 다른 글
| 【알고리즘】 17강. RNN 알고리즘 (0) | 2023.06.27 |
|---|---|
| 【알고리즘】 21-1강. 프롬프트 엔지니어링 (0) | 2023.04.03 |
| 【알고리즘】 7-2강. UMAP(uniform manifold approximation and projection) (0) | 2022.05.19 |
| 【알고리즘】 27강. 기타 알고리즘 (0) | 2022.01.11 |
| 【알고리즘】 12-1강. DIP(Deep Image Prior) (0) | 2021.12.31 |


최근댓글