16강. 합성곱 신경망(convolutional neural network; CNN)
추천글 : 【알고리즘】 알고리즘 목차
1. 개요 [목차]
⑴ 개념
① CNN : 기존 영상 처리의 필터기능(convolution)과 신경망(neural network)을 결합한 심층신경망
② 합성곱 신경망이라고도 함
③ 일반적인 CNN 알고리즘은 1억 개의 파라미터를 가짐
④ 일반적인 CNN 알고리즘의 layer는 10-20개로 구성
⑵ 도입 배경
① 완전연결계층(fully-connected layer) : 보편근사이론에 따르면 CNN이라는 특수한 아키텍처가 없어도 이미지 등의 패턴을 인식 가능
② 다만, fully-connected layer는 파라미터가 너무 많이 필요해 computing burden이 크고 학습시간이 오래 걸림
③ fully-connected layer는 사실상 CNN의 특수한 예에 해당함
⑶ 가정
① 가정 1. spatial locality : 이미지 전체가 아닌 일부분에 국한하여 얻은 패턴들로 빠짐없이 전체 사물의 패턴을 알아낼 수 있는 것
② 가정 2. positional invariance : 위치나 시선각에 따라서 동일한 패턴을 인식할 것이라는 것
⑷ 순서
① 예 1. augmentation_layer → Input → Conv2D, MaxPooling2D, 기타
② 예 2. 입력 - 임베딩 - 컨볼루션 - 맥스풀 - 컨볼루션2 - 맥스풀 - ReLU - Linear(fc) - 아웃풋
○ 임베딩 : one hot vector를 dense vector로 바꿔주는 층
③ nested conv-layers : low-level features → mid-level features → high-level features → trainable classifier
⑸ 활성화 함수(activation function)
① identity : 이 형태를 linear classifier라고 함
② sigmoid σ(x) = 1 / (1 + e-x)
③ tanh(x)
④ ReLU (rectified linear unit) : max(0, x). 가장 자주 사용됨
⑤ leaky ReLU : max(0.1x, x)
⑥ maxout : max(w1Tx + b1, w2Tx + b2)
⑦ elu (exponential linear unit) : x if x ≥ 0; α(ex - 1) if x < 0
⑧ softmax
2. 구성 [목차]
⑴ 구성 1. Input : 입력층
⑵ 구성 2. augmentation_layer
① 정의 : random cropping, random rotation 등의 변형으로 입력을 보다 다양하게 만듦
② 목적 : 이를 통해 모델이 더욱 robust 하게 학습하도록 함
③ 참고 : https://www.tensorflow.org/tutorials/images/data_augmentation
데이터 증강 | TensorFlow Core
도움말 Kaggle에 TensorFlow과 그레이트 배리어 리프 (Great Barrier Reef)를 보호하기 도전에 참여 데이터 증강 개요 이 튜토리얼에서는 이미지 회전과 같은 무작위(그러나 사실적인) 변환을 적용하여 훈
www.tensorflow.org
⑶ 구성 3. convolutional_layer : Conv2D 등
model = tf.keras.Sequential([
...
layers.Conv2D(filters=96, kernel_size=3, activation='elu', strides=2),
...
])
① 목적 : local pattern을 식별하기 위함
② 입력 : W × H × C의 입력이 주어짐
○ W : 너비(width)
○ H : 높이(height)
○ C : 입력측의 채널 수 (예 : RGB 채널)
③ 파라미터 : 총 네 개의 hyperparameter가 필요함
○ K : 필터의 개수. 즉 출력측의 채널 수 (예 : RGB 채널). 필터는 커널(kernel)이라고도 함
○ F : 필터의 크기. kernel_size라고도 함
○ S : 스트라이드(stride). 지정된 간격으로 필터를 순회하는 간격
○ P : 패딩 또는 제로 패딩(zero padding). 이미지의 축소를 방지하기 위해 경곗값에 0인 픽셀을 덧대는 전처리 방식
○ pooling_layer에 비해 spatial extent가 없는 대신 padding이나 kernel_size가 있음
○ 파라미터의 개수 = 필터에 필요한 파라미터의 수 = K(F2C + 1)
○ CNN 딥러닝 알고리즘에서는 이러한 파라미터를 학습하게 됨
④ 연산 : 매 inner product마다 정규화를 거침
○ 이유 : 각 벡터의 절댓값이 아니라 두 벡터 간 코사인 각이 중요하므로
○ 연산의 예시 : 아래 예시에서 선끼리 연결된 것은 곱이고 선 간에는 합이 적용
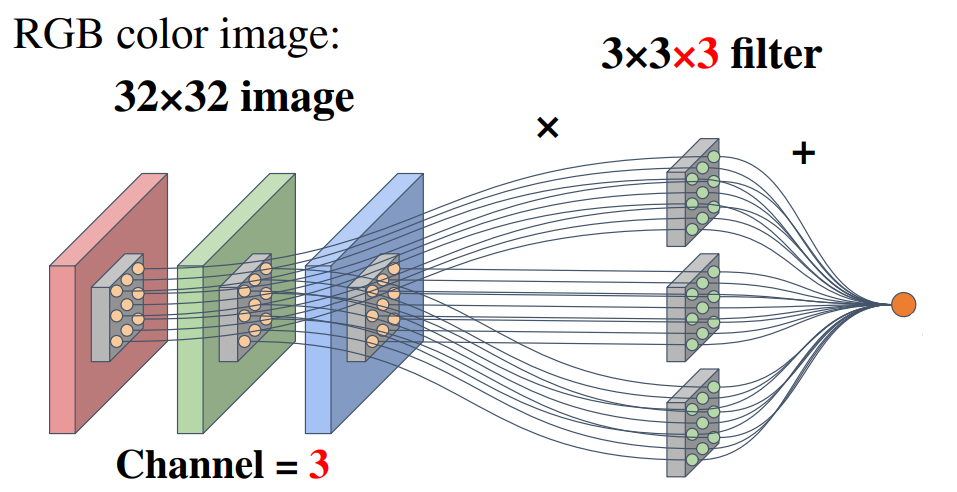
(단, 위 그림에서 바이어스가 생략돼 있음을 유의)
⑤ 필터 : 일반적으로 3 × 3 filter를 많이 씀
○ 필터가 크면 맵은 빠르게 작아짐
○ 이미지가 크면 너무 computation이 많이 필요해짐
○ 필터 크기는 대부분 홀수
○ 1 × 1 conv : 채널 간의 차이를 알기 위해 사용함
⑥ 출력 : convolutional layer의 출력 사이즈를 W' × H' × K라고 하면,
○ W' = (W - F + 2P) / S + 1
○ H' = (H - F + 2P) / S + 1
○ (참고) fully-connected인 경우 총 필요한 파라미터의 수 = (W × H × C + 1) × (W' × H' × K)
○ (주석) 위 W', H' 식에서 "+1"은 천천히 커널을 한 칸씩 움직일 때 마지막으로 움직이는 한 칸을 나타냄
○ 만일 S = 1, P = (F-1) / 2이면 W' = W, H' = H가 됨 : 이 경우 파이썬 상에서 다음과 같이 표시함
model = tf.keras.Sequential([
...
layers.Conv2D(filters=96, kernel_size=3, activation='elu', strides=1, padding='same'),
...
])
⑦ 출력 예시

Figure. 2. convolutional layer에 의한 CNN 출력 예시
⑷ 구성 4. pooling_layer
model = tf.keras.Sequential([
...
layers.MaxPooling2D((2,2), strides=2),
...
])
① 목적 : 입력 차원을 줄이기 위함
② 입력 : W × H × C의 입력이 주어짐
○ W : 너비(width)
○ H : 높이(height)
○ C : 입력측의 채널 수 (예 : RGB 채널)
③ 파라미터 : 총 두 개의 hyperparameter가 필요함
○ F : spatial extent
○ S : stride
○ 보통 F = S = 2로 설정
○ convolutional_layer에 비해 padding이나 kernel_size가 없는 대신 spatial extent가 있음
○ 파라미터의 개수 = 0
○ 이유 : averaging 등 학습이 필요하지 않은 단순한 연산이 수행되기 때문
○ 연산의 종류 : max pooling (e.g., MaxPooling2D), average pooling
④ 출력 : pooling layer의 출력 사이즈를 W' × H' × K라고 하면,
○ W' = (W - F) / S + 1
○ H' = (H - F) / S + 1
⑸ 구성 5. 기타
① BatchNormalization : batch data를 normalize하는 데 효과가 꽤 좋음. 필자는 maxpooling 다음에 씀
② Flatten
③ Dense
④ Dropout
3. 모델 [목차]
⑴ 예 1. TensorFlow API
tf.keras.layers.Conv2D(
filters,
kernel_size,
strides=(1,1),
padding="valid",
data_format=None,
dilation_rate=(1,1),
groups=1,
activation=None,
use_bias=True,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
⑵ 예 2. U-net
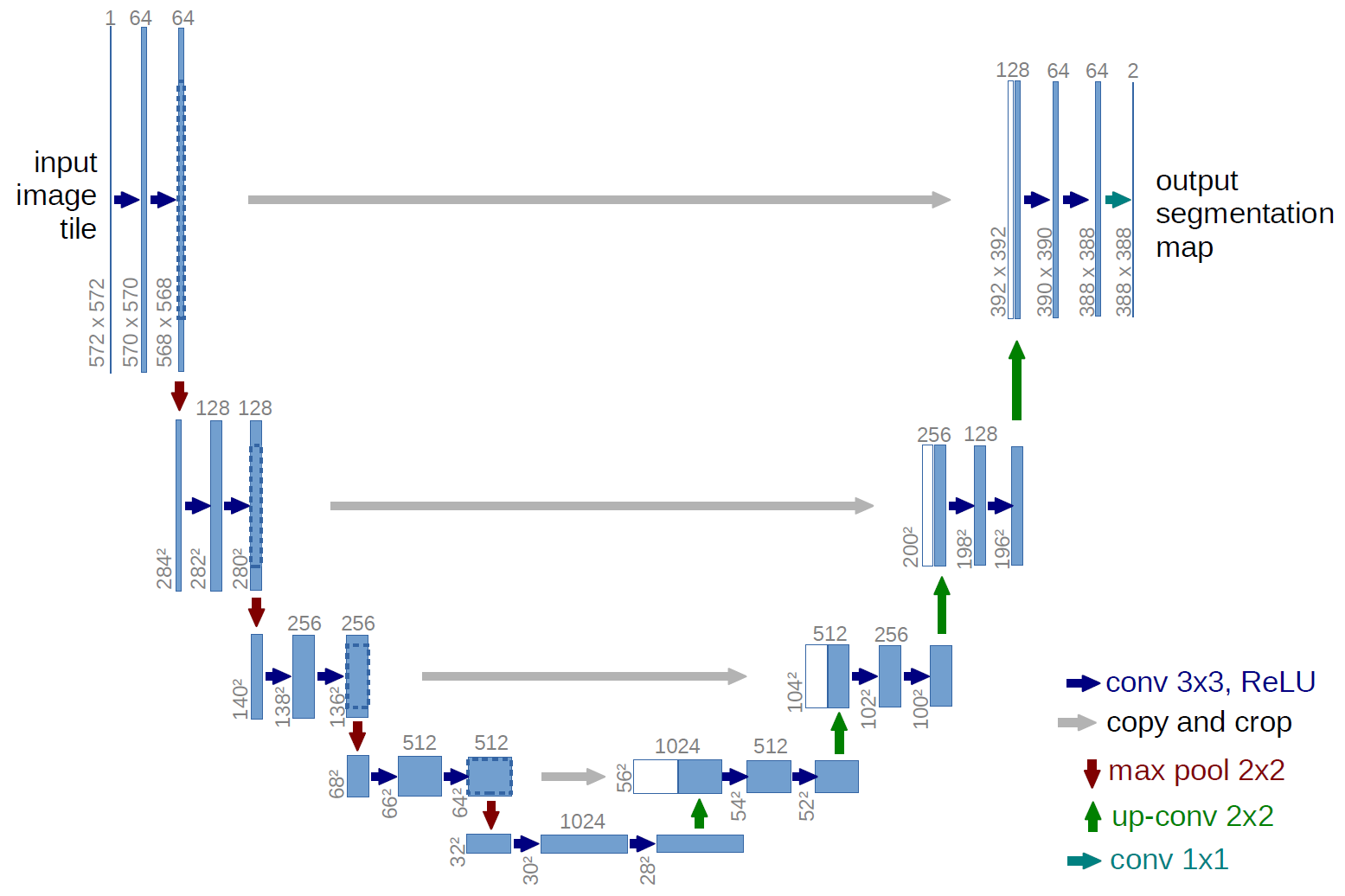
Figure. 3. U-net의 구조
① biomedical 이미지에서 자주 사용
⑶ 예 3. AlexNet
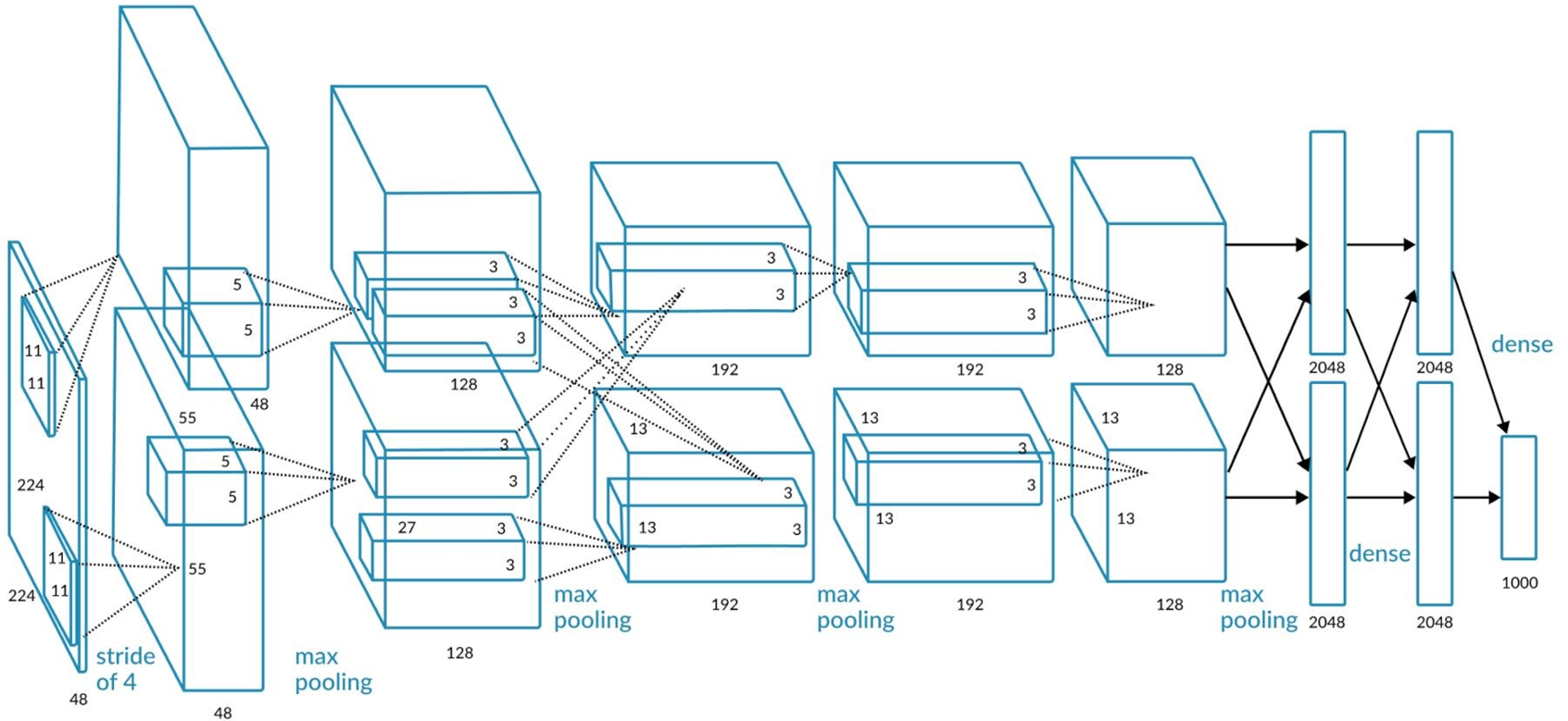
Figure. 4. AlexNet의 구조
① 가장 왼쪽에 있는 네모 박스가 입력층
② 입력층에서부터 오른쪽에 있는 네모 박스를 각각 CONV1, ···, CONV5라고 함
③ maxpooling은 왼쪽부터 POOL1, ···, POOL3라고 함
④ 가장 오른쪽에 있는 maxpooling, dense, dense라고 쓰인 부분의 네트워크를 각각 FC6, FC7, FC8라고 함
⑤ ImageNet을 트레이닝 데이터셋으로 함
⑷ 예 4. Znet : 2차원 U-net을 3차원으로 확장한 것
⑸ 예 5. DIP(deep image prior)
4. 예제 [목차]
⑴ 예 1. ImageNet
① computer vision 연구를 위해 레이블링을 한 것
② WordNet에서 영감을 얻은 것
③ Fei Fei Li에 의해 창안
④ 1000개 카테고리에 100만 개 이상의 이미지가 포함
⑵ 예 2. CIFAR-10
① 유명한 장난감 이미지 분류 데이터셋
② 가로와 세로가 32 픽셀인 60,000개의 작은 RGB 이미지로 구성됨
③ 이미지의 클래스는 총 10개
○ airplane
○ automobile
○ bird
○ cat
○ deer
○ dog
○ frog
○ horse
○ ship
○ truck
④ 60,000개의 이미지 중 50,000개는 training set이고 10,000개는 test set
입력: 2021.12.01 10:50
수정: 2022.11.21 01:18
'▶ 자연과학 > ▷ 알고리즘·머신러닝' 카테고리의 다른 글
| 【알고리즘】 23강. 베이지안 최적화와 MAB (0) | 2021.12.10 |
|---|---|
| 【알고리즘】 7강. 차원 축소 알고리즘 (0) | 2021.12.03 |
| 【알고리즘】 15강. 다층 퍼셉트론 (0) | 2021.11.21 |
| 【알고리즘】 10강. 딥러닝 개요 (0) | 2021.11.21 |
| 【알고리즘】 4강. 데이터 시각화 (0) | 2021.10.28 |




최근댓글