생물정보학 데이터 형식 이해하기
추천글 : 【생물정보학】 생물정보학 분석 목차
1. FASTQ 파일 [본문]
2. FASTA 파일 [본문]
3. GFF 파일 [본문]
4. GTF 파일 [본문]
5. SAM 파일 [본문]
6. BAM 파일 [본문]
7. BED 파일 [본문]
8. Loom 파일 [본문]
9. VCF 파일 [본문]
10. 기타 파일 [본문]
1. FASTQ(fast-Q) [목차]
@SEQ_ID
GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT
+
!''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65
⑴ 샘플의 시퀀스 정보를 저장
⑵ 첫 번째 행 : SEQ_ID, 즉 @ + 시퀀스 식별자(sequence identifier) + 추가 설명(optional description)
① 예 1. @HWUSI-EAS100R:6:73:941:1973#0/1
| HWUSI-EAS100R | the unique instrument name |
| 6 | flowcell lane |
| 73 | tile number within the flowcell lane |
| 941 | 'x'-coordinate of the cluster within the tile |
| 1973 | 'y'-coordinate of the cluster within the tile |
| #0 | index number for a multiplexed sample (0 for no indexing) |
| /1 | the member of a pair, /1 or /2 (paired-end or mate-pair reads only) |
Table. 1. SEQ_ID 예시 (ref)
② 예 2. @EAS139:136:FC706VJ:2:2104:15343:197393 1:Y:18:ATCACG
| EAS139 | the unique instrument name |
| 136 | the run id |
| FC706VJ | the flowcell id |
| 2 | flowcell lane |
| 2104 | tile number within the flowcell lane |
| 15343 | 'x'-coordinate of the cluster within the tile |
| 197393 | 'y'-coordinate of the cluster within the tile |
| 1 | the member of a pair, 1 or 2 (paired-end or mate-pair reads only) |
| Y | Y if the read is filtered (did not pass), N otherwise |
| 18 | 0 when none of the control bits are on, otherwise it is an even number |
| ATCACG | index sequence |
Table. 2. SEQ_ID 예시 (ref)
⑶ 두 번째 행 : raw sequence
⑷ 세 번째 행 : "+" + (optional) 시퀀스 식별자
⑸ 네 번째 행 : 두 번째 행의 시퀀스에 대한 퀄리티 스코어(quality score)
① Phred 퀄리티 스코어 = Q = Qsanger = -10 log10 P (단, P는 base call error probability)
○ 예 1. 1 error in 1000 = Qsanger 30
○ 예 2. 1 error in 10000 = Qsanger 40
② ASCII 문자로 표현되며 raw sequence와 문자 개수가 동일함
③ 종류 1. PHRED 33 encoding
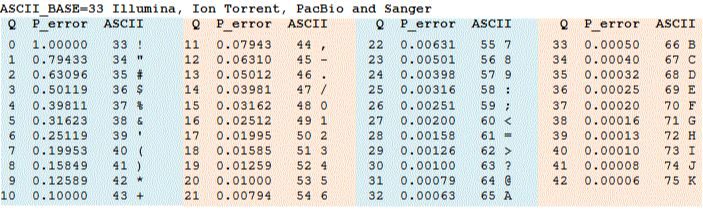
Table. 3. PHRED 33 encoding
○ 현재 대부분 사용되는 형식
○ Phred score에 33을 더한 뒤 ASCII 코드로 나타낸 것 : 즉, 0-93을 ASCII 33-126과 대응시킴
④ 종류 2. PHRED 64 encoding
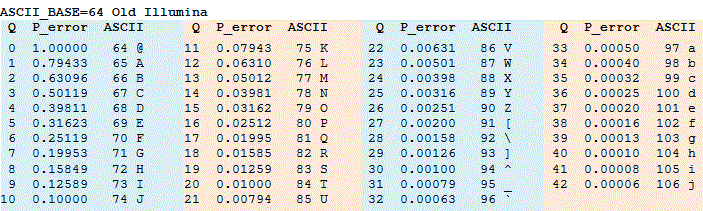
Table. 4. PHRED 64 encoding
2. FASTA(fast-A) [목차]
⑴ 개요
① 레퍼런스의 시퀀스 정보를 저장
② 헤더 라인은 ">" 기호로 시작
③ DNA, RNA, protein 모두에 사용 가능
⑵ 예 : GFP에 대한 FASTA 파일
>L29345.1 Aequorea victoria green-fluorescent protein (GFP) mRNA, complete cds
TACACACGAATAAAAGATAACAAAGATGAGTAAAGGAGAAGAACTTTTCACTGGAGTTGTCCCAATTCTT
GTTGAATTAGATGGCGATGTTAATGGGCAAAAATTCTCTGTCAGTGGAGAGGGTGAAGGTGATGCAACAT
ACGGAAAACTTACCCTTAAATTTATTTGCACTACTGGGAAGCTACCTGTTCCATGGCCAACACTTGTCAC
TACTTTCTCTTATGGTGTTCAATGCTTTTCAAGATACCCAGATCATATGAAACAGCATGACTTTTTCAAG
AGTGCCATGCCCGAAGGTTATGTACAGGAAAGAACTATATTTTACAAAGATGACGGGAACTACAAGACAC
GTGCTGAAGTCAAGTTTGAAGGTGATACCCTTGTTAATAGAATCGAGTTAAAAGGTATTGATTTTAAAGA
AGATGGAAACATTCTTGGACACAAAATGGAATACAACTATAACTCACATAATGTATACATCATGGCAGAC
AAACCAAAGAATGGAATCAAAGTTAACTTCAAAATTAGACACAACATTAAAGATGGAAGCGTTCAATTAG
CAGACCATTATCAACAAAATACTCCAATTGGCGATGGCCCTGTCCTTTTACCAGACAACCATTACCTGTC
CACACAATCTGCCCTTTCCAAAGATCCCAACGAAAAGAGAGATCACATGATCCTTCTTGAGTTTGTAACA
GCTGCTGGGATTACACATGGCATGGATGAACTATACAAATAAATGTCCAGACTTCCAATTGACACTAAAG
TGTCCGAACAATTACTAAATTCTCAGGGTTCCTGGTTAAATTCAGGCTGAGACTTTATTTATATATTTAT
AGATTCATTAAAATTTTATGAATAATTTATTGATGTTATTAATAGGGGCTATTTTCTTATTAAATAGGCT
ACTGGAGTGTAT
3. GFF(general feature format) [목차]
⑴ 개요
① 레퍼런스의 annotation 정보를 저장. GTF와 약간의 형식 차이가 있음
② 1-start, fully closed
○ 단, UCSC Genome Browser와 같은 웹 브라우저의 경우 0-start, half-open
| rs782519173 (hg38) | start | end |
| positioned in web browser (1-start, fully-closed) |
133255708 | 133255708 |
| stored in table (0-start, half-open) |
133255707 | 133255708 |
Table. 5. zero-based vs one-based
③ 첫 8개의 GFF 필드는 seqname(#seqid), source, feature(type), start, end, score, strand, phase, attributees : GTF와 동일
○ seqname : 염색체 또는 스캐폴드의 이름
○ source : 이 feature를 생성한 프로그램의 이름 또는 데이터 소스
○ feature : feature 유형 이름. 유전자, 변이, 유사성 등
○ start : feature의 시작 위치. 서열 번호는 1부터 시작
○ end : feature의 종료 위치(포함). 서열 번호는 1부터 시작. non-coding RNA의 경우 start와 end 위치가 동일함. 언제나 start보다 크거나 같음
○ score : 부동 소수점 값
○ strand : + (정방향) 또는 - (역방향)으로 정의됨. strand가 +이면 start가 TSS(transcription start site)이고, strand가 -이면 end가 TSS가 됨
○ frame : '0', '1', '2' 중 하나. '0'은 feature의 첫 번째 염기가 코돈의 첫 번째 염기임을 나타내는 식
○ attribute : 태그-값 쌍이 세미콜론으로 구분된 목록. 각 feature에 대한 추가 정보를 제공
④ GTF와 달리 추가적인 필드가 없음 : 예를 들어, gene_id와 transcript_id 사이의 계층 관계는 GFF에서 보존되지 않음
import sys
inFile = open(sys.argv[1],'r')
for line in inFile:
#skip comment lines that start with the '#' character
if line[0] != '#':
#split line into columns by tab
data = line.strip().split('\t')
#parse the transcript/gene ID. I suck at using regex, so I usually just do a series of splits.
transcriptID = data[-1].split('transcript_id')[-1].split(';')[0].strip()[1:-1]
geneID = data[-1].split('gene_id')[-1].split(';')[0].strip()[1:-1]
#replace the last column with a GFF formatted attributes columns
#I added a GID attribute just to conserve all the GTF data
data[-1] = "ID=" + transcriptID + ";GID=" + geneID
#print out this new GFF line
print '\t'.join(data)
import sys
inFile = open(sys.argv[1],'r')
for line in inFile:
#skip comment lines that start with the '#' character
if line[0] != '#':
#split line into columns by tab
data = line.strip().split('\t')
ID = ''
#if the feature is a gene
if data[2] == "gene":
#get the id
ID = data[-1].split('ID=')[-1].split(';')[0]
#if the feature is anything else
else:
# get the parent as the ID
ID = data[-1].split('Parent=')[-1].split(';')[0]
#modify the last column
data[-1] = 'gene_id "' + ID + '"; transcript_id "' + ID
#print out this new GTF line
print '\t'.join(data)
4. GTF(gene transfer format) [목차]
⑴ 개요
① 레퍼런스의 annotation 정보를 저장
② 첫 8개의 필드는 GFF와 동일함
③ GTF는 feature column에서 GFF에 더하여 5UTR, 3UTR, inter, inter_CNS, intron_CNS를 포함
④ group 필드는 attribute들의 리스트 : attribute는 ;로 끝나고 정확히 1개의 스페이스로 구분됨
⑵ 예 : MUC1 유전자 및 한 개의 transcript에 대한 GTF 파일 내용
NC_000001.11 BestRefSeq gene 155185824 155192915 . - . gene_id "MUC1"; transcript_id ""; db_xref "GeneID:4582"; db_xref "HGNC:HGNC:7508"; db_xref "MIM:158340"; description "mucin 1, cell surface associated"; gbkey "Gene"; gene "MUC1"; gene_biotype "protein_coding"; gene_synonym "ADMCKD"; gene_synonym "ADMCKD1"; gene_synonym "ADTKD2"; gene_synonym "CA 15-3"; gene_synonym "Ca15-3"; gene_synonym "CD227"; gene_synonym "EMA"; gene_synonym "H23AG"; gene_synonym "KL-6"; gene_synonym "MAM6"; gene_synonym "MCD"; gene_synonym "MCKD"; gene_synonym "MCKD1"; gene_synonym "MUC-1"; gene_synonym "MUC-1/SEC"; gene_synonym "MUC-1/X"; gene_synonym "MUC1/ZD"; gene_synonym "PEM"; gene_synonym "PEMT"; gene_synonym "PUM";
NC_000001.11 BestRefSeq transcript 155185824 155192915 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gbkey "mRNA"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA";
NC_000001.11 BestRefSeq exon 155192786 155192915 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "1";
NC_000001.11 BestRefSeq exon 155192183 155192310 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "2";
NC_000001.11 BestRefSeq exon 155188008 155188063 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "3";
NC_000001.11 BestRefSeq exon 155187722 155187858 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "4";
NC_000001.11 BestRefSeq exon 155187455 155187576 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "5";
NC_000001.11 BestRefSeq exon 155187225 155187374 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "6";
NC_000001.11 BestRefSeq exon 155185824 155186209 . - . gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "GeneID:4582"; gene "MUC1"; product "mucin 1, cell surface associated, transcript variant 15"; transcript_biotype "mRNA"; exon_number "7";
NC_000001.11 BestRefSeq CDS 155192786 155192843 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "1";
NC_000001.11 BestRefSeq CDS 155192183 155192310 . - 2 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "2";
NC_000001.11 BestRefSeq CDS 155188008 155188063 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "3";
NC_000001.11 BestRefSeq CDS 155187722 155187858 . - 1 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "4";
NC_000001.11 BestRefSeq CDS 155187455 155187576 . - 2 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "5";
NC_000001.11 BestRefSeq CDS 155187225 155187374 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "6";
NC_000001.11 BestRefSeq CDS 155186138 155186209 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "7";
NC_000001.11 BestRefSeq start_codon 155192841 155192843 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "1";
NC_000001.11 BestRefSeq stop_codon 155186135 155186137 . - 0 gene_id "MUC1"; transcript_id "NM_001204291.1"; db_xref "CCDS:CCDS72934.1"; db_xref "GeneID:4582"; gbkey "CDS"; gene "MUC1"; note "isoform 15 precursor is encoded by transcript variant 15"; product "mucin-1 isoform 15 precursor"; protein_id "NP_001191220.1"; exon_number "7";
① NM_000001.11 : 레퍼런스의 accession number. "NM_000001"은 1번 염색체를, ".11"은 11번째 버전을 의미함
② BestRefSeq, RefSeq, Gnomon, HAVANA 등 : 레퍼런스 종류
③ GTF의 각 행은 gene, transcript, exon, CDS, domain, group, start_codon, stop_codon 등이 있음
④ 첫 행의 155185825, 155192915는 FASTA 내 155185825번째 염기부터 155192915번째 염기가 MUC1 유전자라는 의미
⑤ +, - : (+)는 forward (= plus, sense) strand에 유전자가 있음을, (-)는 reverse (= minus, antisense) strand에 유전자가 있음
⑥ 0, 1, 2 : CDS에 있는 0, 1, 2는 각각 feature의 1, 2, 3번째 염기가 해독틀의 1번째 코돈이라는 의미
⑦ 하나의 gene에는 하나 이상의 transcript가 있음 : gene과 transcript는 gene_id, gene 등을 통해 서로 연결됨
⑧ 각 transcript에는 여러 개의 exon 수식 부위가 있음 : transcript와 exon은 transcript_id를 통해 서로 연결됨
⑨ CDS(protein coding sequence)는 일반적으로 exon의 부분집합 : 그마저도 CDS = exon인 부분이 상당히 많음
⑩ start_codon, stop_codon이 없는 유전자도 있음 (e.g., LOC102724389)
5. SAM(sequence alignment/MAP format) [목차]
⑴ FASTQ 파일을 reference 파일(e.g., GTF)에 맵핑한 결과를 저장하는 파일
⑵ 해석 : 다음과 같은 행이 계속 줄지어 있음
QNAME (Query template NAME) FLAG RNAME (Reference sequence NAME) POS (1-based leftmost mapping Position) MAPQ (Mapping Quality) CIGAR (Concise Idiosyncratic Gapped Alignment Report) string RNEXT PNEXT TLEN (observed Template LENgth) SEQ (segment SEQuence) QUAL (quality) The number of reported alignments that contain the read. The hit index. Alignment score. Number of mismatches. An additional tag, possibly specific to the aligner or analysis pipeline. Read group identifier. Tags related to the gene or transcript the read is aligned to 'tdtomato'. An additional flag used by specific software. ....20 ....21 ....22 ....23 ....24 ....25 ....26 ....27 ....28 ....29 ...30
A01192:688:HM3FVDMXY:1:2117:20374:35023 1024 tdtomato 1438 255 30S40M20S * 0 0 AAGCAGTGGTATCAACGCAGAGTACATGGGATCACCTGTTCCTGTACGGCATGGATGAGCTGTACAAGTGAGCTGCCTTCTGCGGGGCTT FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF NH:i:1 HI:i:1 AS:i:39 nM:i:0 ts:i:30 RG:Z:CR_23_15103_TS_R_SSV_1:0:1:HM3FVDMXY:1 TX:Z:tdtomato,+1437,30S40M20S GX:Z:tdtomato GN:Z:tdtomato fx:Z:tdtomato RE:A:E xf:i:17 CR:Z:CGGGCAGCTAAACCGC CY:Z:FFFFFFFFFFFFFFFF CB:Z:CGGGCAGCTAAACCGC-1 UR:Z:AATCAGTTATGC UY:Z:FFFFFF,:FFFF UB:Z:AATCAGTTATGC NA
① QNAME (Query template NAME) : query read의 이름. paired-end sequencing의 경우 각 페어의 QNAME이 동일함
② FLAG : bitwise flag (pairing, strand 등)
③ RNAME (Reference sequence NAME) : 레퍼런스 시퀀스 이름. chr1, chr2 chrM 등
④ POS (1-based leftmost mapping Position) : alignment의 1-based leftmost position
⑤ MAPQ (Mapping Quality) : 맵핑 퀄리티 (Phred-scaled)
⑥ CIGAR (Concise Idiosyncratic Gapped Alignment Report) string (operation : MIDNSHP)
Op BAM Description
M 0 alignment match (can be a sequence match or mismatch)
I 1 insertion to the reference
D 2 deletion from the reference
N 3 skipped region from the reference
S 4 soft clipping (clipped sequences present in SEQ)
H 5 hard clipping (clipped sequences NOT present in SEQ)
P 6 padding (silent deletion from padded reference)
= 7 sequence match
X 8 sequence mismatch
⑦ RNEXT
⑧ PNEXT
⑨ TLEN (observed Template LENgth)
⑩ SEQ (segment SEQuence)
⑪ QUAL (quality)
⑫ NH:i : The number of reported alignments that contain the read.
⑬ HI:i : The hit index.
⑭ AS:i : Alignment score.
⑮ nM:i : Number of mismatches.
⑯ ts:i : An additional tag, possibly specific to the aligner or analysis pipeline.
⑰ RG:Z : Read group identifier.
⑱ TX:Z, GX:Z, GN:Z, fx:Z : Tags related to the gene or transcript the read is aligned to your query.
○ GN:Z : gene name tag
⑲ xf:i : An additional flag used by specific software.
⑳ CR:Z, CY:Z, UR:Z, UY:Z, UB:Z : Fields related to cell barcodes and unique molecular identifiers (UMIs), which are important in single-cell sequencing technologies.
㉑ MRNM : mate의 이름. mate의 레퍼런스 이름을 나타냄. NA인 경우 *, 동일한 경우 =로 나타냄
㉒ MPOS : mate의 1-based leftmost position
㉓ ISIZE : 추정된 삽입 서열의 크기
㉔ SEQQuery : 레퍼런스의 서열 (strand의 부호는 동일)
㉕ QUAL : 쿼리의 퀄리티 (Phred-scaled)
6. BAM(binary alignment map) [목차]
⑴ SAM 파일의 binary 버전으로 읽을 수 없음 : 저장 용량이 작으므로 더 선호됨
⑵ 자주 SAM 또는 BAM 파일은 sorted 돼야 함
7. BED 파일 [목차]
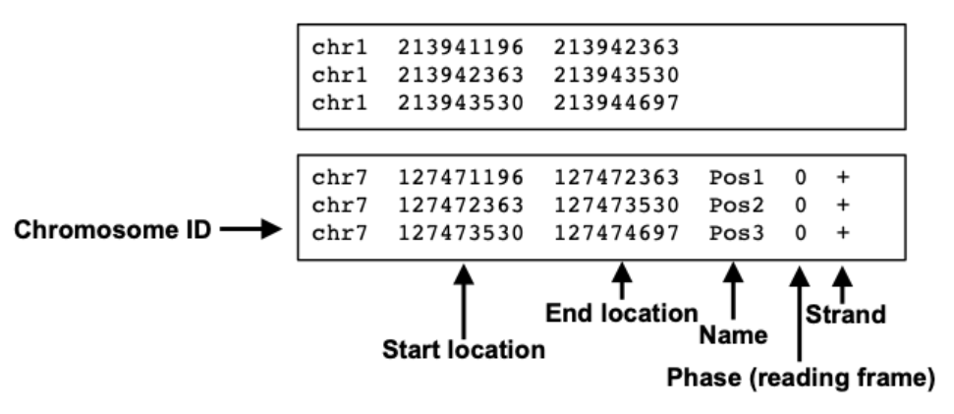
Figure. 1. BED 포맷
⑴ alignment 결과를 나타내는 최소한의 형식
⑵ 인핸서, SNP, ChIP-seq peak, 엑손 등 관심 피처를 표현할 때 매우 유용함
⑶ 탭으로 구분돼 있음(tab-delimited)
⑷ 3개의 필수 필드 : chrom, chromaStart, chromEnd
① chrom : 염색체 이름
② chromStart : 0-offset (‘0’부터 시작). 피처의 시작
③ chromEnd : 1-offset. 피처의 끝
⑸ 9개의 추가 필드 : name, score, strand, thickStart, thickEnd, itemRgb, blockCount, blockSizes, blockStarts
① score : 0-1000 사이의 스코어
② strand : 맵핑 퀄리티 (Phred-scaled)
8. Loom (.loom) [목차]
⑴ gene expression data : .h5 파일의 내용
⑵ (optional) layer for spliced and unspliced RNA transcripts : RNA velocity-aware tool을 쓴 경우
⑶ (optional) layer for cell metadata
⑷ (optional) layer for gene metadata
9. VCF 파일 [목차]
⑴ sample → raw sequence (FASTA / FASTQ) → aligned read (BAM / SAM) → variant call (VCF)
⑵ 파일 구성

Table. 6. VCF 파일 구성
① #CHROM : 염색체 식별자. 예시는 7, chr7, X 또는 chrX 등이 포함
② POS : 기준 위치. 염색체 별로 오름차순으로 정렬됨
③ ID : 세미콜론으로 구분된 고유 식별자. 공백은 허용되지 않음
④ REF : 기준 염기(A, C, G, T). 삽입은 점(.)으로 표시될 수 있음
⑤ ALT : 세미콜론으로 구분된 대체 염기(A, C, G, T). 삭제는 점(.)으로 표시됨
⑥ QUAL : 로그 스케일로 표시된 품질 점수. 100은 오류 확률이 1 in 1010임을 의미
⑦ FILTER : 실패한 필터를 나타내며, 세미콜론으로 구분. PASS 또는 MISSING으로 표시될 수 있음
⑧ INFO : 세미콜론으로 구분된 이름-값 형식의 위치 수준(샘플 비포함) 정보
○ NS(number of sample) : 해당 변이가 발견된 샘플수
○ DP(depth) : 해당 위치에서 읽힌 시퀀스(reads)의 깊이. DP=14는 이 위치에서 총 14개의 시퀀스가 읽혔다는 의미
○ AF(allele frequency) : 대립 유전자의 빈도
○ AA(ancestral allele) : 조상의 대립 유전자
○ DB(dbSNP) : 이 변이가 dbSNP에 등록되었다는 의미
○ H2(HapMap2) : 이 변이가 HapMap2 프로젝트의 데이터베이스에 포함되어 있음을 의미
⑨ FORMAT : 세미콜론으로 구분된 샘플 수준 필드 이름 선언
○ GT(genotype) : 슬래시(/, unphased) 또는 세로줄(|, phased)로 구분된 대립유전자를 나타냄
○ GQ : 단일 정수로 표현되는 유전자형 품질
○ DP : 단일 정수로 표현되는 읽기 깊이
○ HQ : 두 개의 정수로 구성된 반수체 품질. 쉼표로 구분됨
⑩ <SAMPLE DATA> : FORMAT 필드 선언에 해당하는 세미콜론으로 구분된 샘플 수준 필드 데이터
⑶ 해석
① 모든 변이는 NCBI36 (hg18)에서 염색체 20에 발생
② 5개의 SNP 위치가 확인됨 (14370, 17330, 1110696, 1230237, 1234567)
③ 3개의 변이는 ID가 있으며, 여기에는 2개의 dbSNP 레코드(rs6054257, rs6040355)가 포함
④ 첫 두 위치(14370, 17330)는 단순한 단일 염기 쌍 치환
⑤ 세 번째 위치는 2개의 대체 대립유전자(G와 T)를 포함하며, 기준 염기(A)를 대체
⑥ 네 번째 위치는 T의 삭제를 나타내며, 대체 대립유전자가 누락되어 있음 (“.”).
⑦ 다섯 번째 행에는 두 개의 대체 대립유전자가 있음 : 첫 번째는 TC의 삭제이고, 두 번째는 T의 삽입
⑷ 압축 : HTSlib 이용
① 방법 1. bgzip MyFile.vcf
② 방법 2. tabix -p vcf MyFile.vcf.gz (인덱싱)
③ 방법 3. tabix -h MyFile.vcf.gz chr1:5363-5463 (특정 염색체 부분에 대해)
10. 기타 파일 [목차]
⑴ HDF(hierarchical data format)
⑵ CRAM
⑶ Flat
⑷ AGP
⑸ GB/GBK
⑹ BEDgraph : variant calling과 관련

Figure. 2. BEDgraph 포맷
⑺ Wiggle : variant calling과 관련. Wiggle 파일을 binary 형식으로 저장한 형식을 bigWig 포맷이라고 함
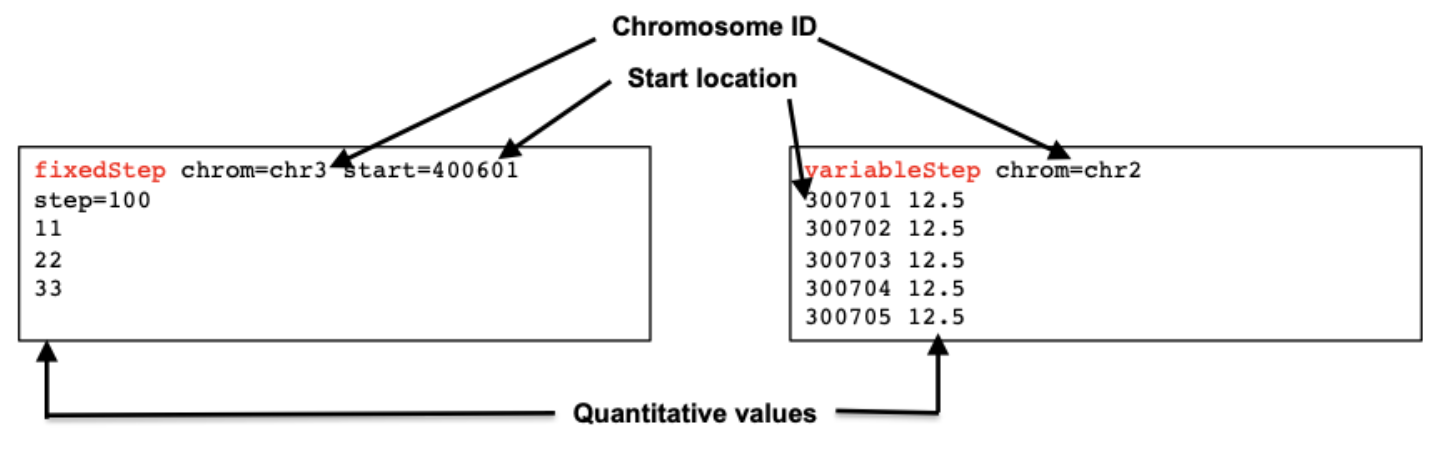
Figure. 3. Wiggle 포맷
⑻ GFA(Graphical fragment assembly format) : assembly graph를 나타내기 위한 파일. 자주 사용하지는 않음
① H (header) : 고정값은 없음
② S (segment) : vertex와 이것의 complement를 나타냄. 고정값은 segName, segSeq
③ L (overlap) : edge와 이것의 complement를 나타냄. 고정값은 segName1, segOri1, segName2, segOri2, CIGAR
⑼ FASTG : assembly graph를 나타내기 위한, GFA 이전의 파일 포맷
① 용어가 다소 다름 : 실제 vertex를 edge로 표현하고, edge를 adjancy로 표현함
② subgraph를 nesting으로 표현할 수 있음 : 이것을 다루는 알고리즘이 없어 FASTG의 주요 한계로 지적됨
⑽ PAF
⑾ tagAlign
⑿ SJ.out.tab
| chr1 | 1564692 | 1565018 | 1 | 1 | 1 | 2 | 0 | 6 |
| chr1 | 1564947 | 1565018 | 1 | 1 | 1 | 2 | 0 | 24 |
| chr1 | 1565085 | 1565671 | 1 | 1 | 1 | 15 | 0 | 22 |
| chr1 | 1571844 | 1572043 | 2 | 2 | 1 | 17 | 0 | 21 |
| chr1 | 1572161 | 1572258 | 2 | 2 | 1 | 5 | 0 | 5 |
| chr1 | 1572367 | 1572442 | 2 | 2 | 1 | 13 | 0 | 20 |
Table. 7. SJ.out.tab 파일 예시
① column 1 : chromosome
② column 2 : first base of the intron (1-based)
③ column 3 : last base of the intron (1-based)
④ column 4 : strand (0 : undefined, 1 : +, 2 : -). column 5와 상당히 높은 상관관계
⑤ column 5 : intron moif. 0: non-canonical; 1: GT/AG, 2: CT/AC, 3: GC/AG, 4: CT/GC, 5: AT/AC, 6: GT/AT
⑥ column 6 : 0: unannotated, 1: annotated (only if splice junctions database is used)
⑦ column 7 : number of uniquely mapping reads crossing the junction
⑧ column 8 : number of multi-mapping reads crossing the junction
⑨ column 9 : maximum spliced alignment overhang. 가장 확실하게 스플라이싱된 리드
⒀ fam : PLINK 포맷
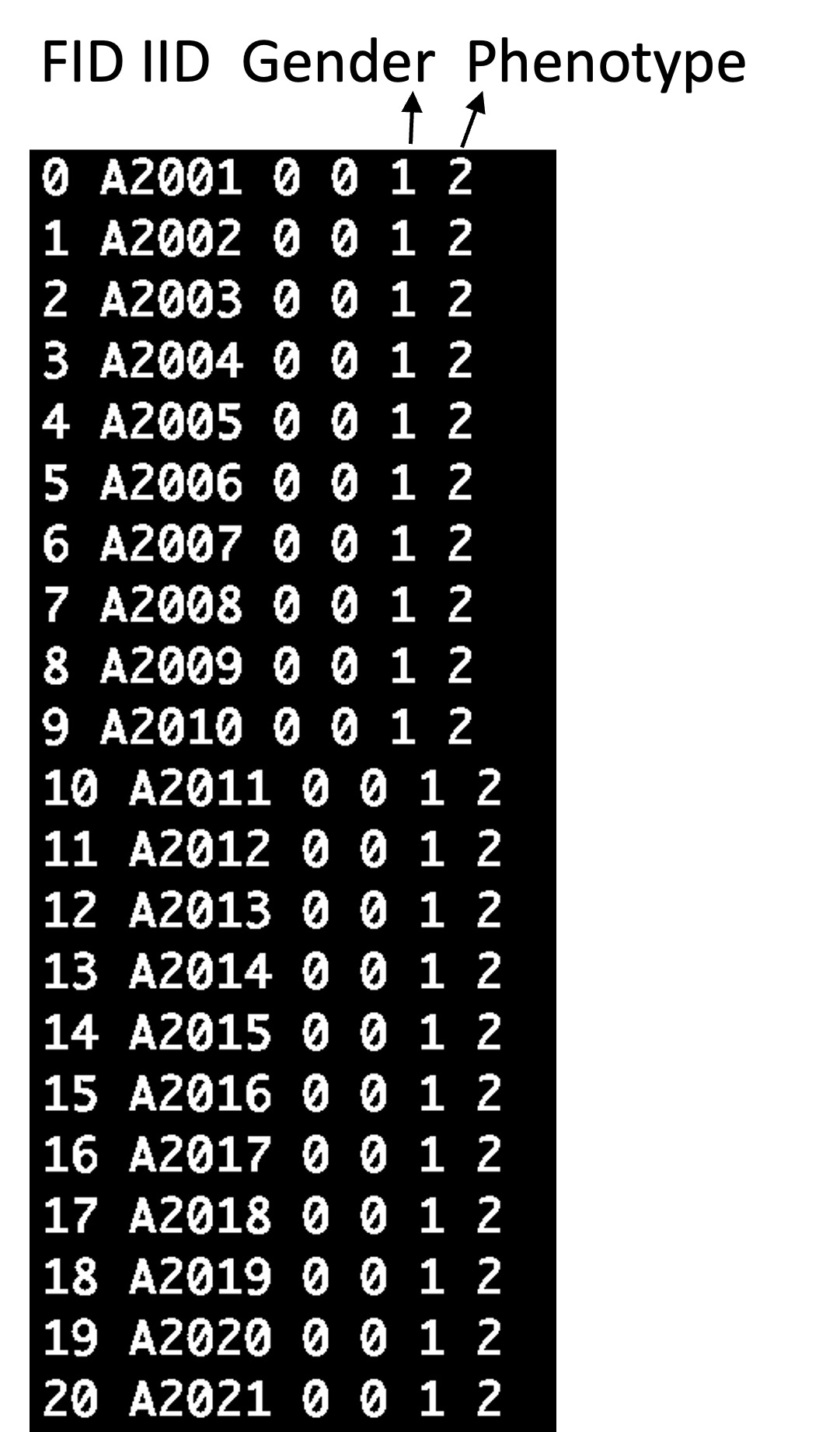
Figure. 4. fam 파일
⒁ bim : PLINK 포맷

Figure. 5. bim 파일
입력: 2023.08.03 17:05
수정: 2024.02.02 21:56
'▶ 자연과학 > ▷ 생물정보학' 카테고리의 다른 글
| 【생물정보학】 생물 라이브러리 (0) | 2023.12.11 |
|---|---|
| 【생물정보학】 HDF 파일과 filtered_feature_bc_matrix.h5 (3) | 2023.10.17 |
| 【생물정보학】 셀 타입 마커 유전자 (2) | 2023.07.05 |
| 【생물정보학】 RNA 시퀀싱 quality control (QC) (0) | 2023.05.22 |
| 【생물정보학】 모델 생물 라이브러리 (0) | 2022.07.20 |



최근댓글