논리 추론 모델
추천글 : 【논리학】 논리학 목차
a. 거대언어모델(LLM)
b. AI Scientist
최근 LLM을 이용해 가설을 만들거나 논리적 추론을 하는 인공지능이 유행이다. 이들을 통틀어 AI Scientist라고 일컫는 것 같다. 예를 들어, Google Deepmind의 FunSearch를 시작으로 OpenAI o1/o3, Gemini Thinking, Claude Sonnet Thinking, DeepSeek-R1, AI-Descartes, Theorizer 등이 있었고, 최근에는 LLM 에이전트를 이용해 AutoDiscovery, The Virtual Lab 등이 발표되었다. 2026년을 AI 에이전트의 원년이라고도 하고, 스탠포드 컴공과는 거의 다 LLM 에이전트 연구에 몰입하고 있다. 하지만, 논리 추론(reasoning)에 있어서 LLM 에이전트가 적합한지를 검토하고자 한다.
최근 2015년부터 수집해 온 논리학 문제들로부터 주어진 문제 상황으로부터 얻을 수 있는 명제를 빠짐 없이 정확하게 도출할 수 있는 논리학 문제 23개를 큐레이션하였다. 이 문제집에는 문제, 답안, 난이도가 담겨 있다.
8개의 solver로 답안을 최대한 많이 도출한 뒤 이를 3개의 verifier로 검증하여 주어진 정보로부터 추출할 수 있는 명제들을 exhaustive하고 accurate하게 도출하려고 시도했다. ChatGPT 4o로 구현하였다. 이로부터 TP (true positive), FP (false positive), FN (false negative)를 ChatGPT 5.4 Thinking으로 뽑아낸 뒤 (TN (true negative)은 당연히도 뽑아낼 수 없다), precision, recall을 계산하였다. 그 결과는 다음과 같았다.
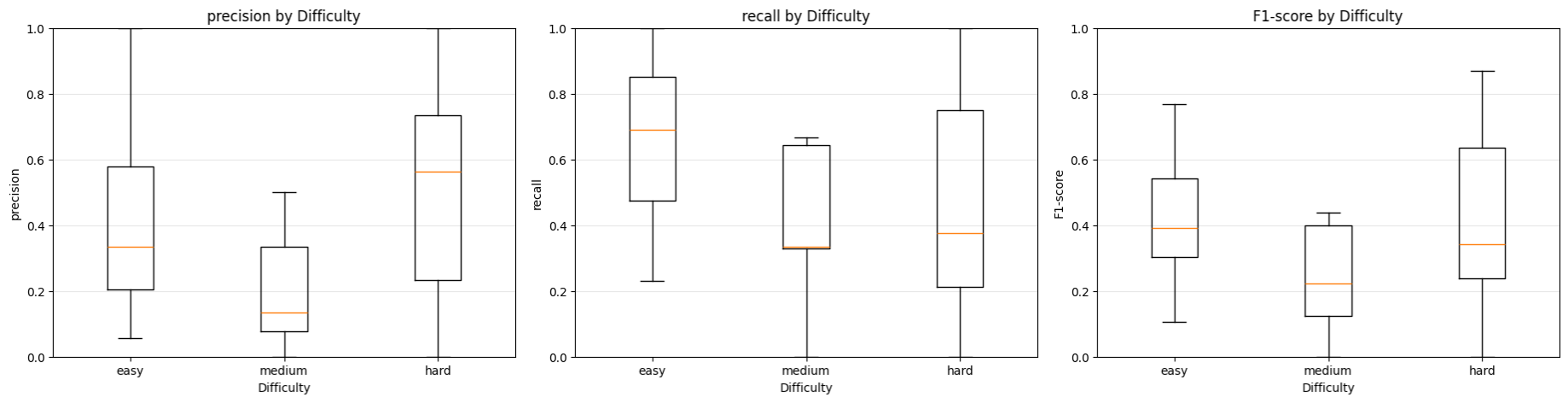
원래는 80 ~ 90점 정도를 예상했는데, 40 ~ 60점을 받은 느낌이었다. 그러나 특히 어려웠던 금붕어 문제(풀이)의 경우 ChatGPT 5.4 Thinking은 1분도 안 되어 정확하게 답을 도출했던 것을 알 수 있었다. (보통 박사급 인력 기준으로 10 ~ 30분 정도 소요되는 문제이다)
다음 상황을 전제로 금붕어를 기르는 사람은 누구일까?
[상황 1]
1. 5채의 서로 다른 색깔의 집이 있다.
2. 각 집에는 서로 다른 국적의 사람이 산다.
3. 각 집 주인들은 서로 다른 종류의 음료수를 마신다.
4. 각 집 주인들은 서로 다른 종류의 담배를 피운다.
5. 각 집 주인들은 서로 다른 애완동물을 기른다.
[상황 2]
1. 영국인은 빨간색 집에 산다.
2. 스웨덴인은 개를 기른다.
3. 덴마크인은 홍차를 마신다.
4. 녹색 집은 흰색 집 왼쪽에 위치해 있다.
5. 녹색 집 사람은 커피를 마신다.
6. 팰맬(Pall Mall) 담배를 피우는 사람은 새를 기른다.
7. 노란색 집 사람은 던힐(Dunhill) 담배를 피운다.
8. 한 가운데 사는 사람은 우유를 마신다.
9. 노르웨이인은 첫 번째 집에 산다.
10. 블렌드(Blend) 담배를 피우는 사람은 고양이를 기르는 사람 옆집에 산다.
11. 말을 기르는 사람은 던힐(Dunhill) 담배를 피우는 사람 옆집에 산다.
12. 블루 매스터(Blue Master) 담배를 피우는 사람은 맥주를 마신다.
13. 독일인은 프린스(Prince) 담배를 피운다.
14. 노르웨이인은 파란색 집 옆집에 산다.
15. 블렌드(Blend) 담배를 피우는 사람은 물을 마시는 사람 옆집에 산다.
결국 논리 추론 AI는 여러 덜 똑똑한 에이전트들의 토론이 아니라 하나의 더 똑똑한 AI로 구현해야만 한다는 결론을 얻게 되었다. 이는 예전에 `가설을 생성하는 AI, 그 아이디어의 시작`이라는 글을 쓸 적에 다음 문제를 조명하면서 제기한 통찰이기도 하다.
"크기와 모양이 같은 6개의 구슬이 있다. 이 중에서 3개는 무겁고, 나머지 3개는 가볍다. 단, 무거운 3개의 무게는 서로 같고, 가벼운 3개의 무게는 서로 같다. 이때, 양팔저울을 3번 써서 구슬을 무거운 것과 가벼운 것으로 구별하여라."
이 문제를 풀 때 각각의 게임을 독립된 것으로 보고 거기서 얻어지는 정보의 교집합으로 보는 게 아니라, 한 게임에서 얻어진 정보를 다른 게임에 전달하고, 그렇게 게임을 진행하면서 정보가 누적되면서 훨씬 더 다채로운 결론이 만들어질 수 있다는 게 요지이다. 결국 논리 추론 AI는 동시게임이 아니라 순차게임이고, 오픈 루프가 아니라 피드백 루프이며, chain-of-thought로 구현돼야 함을 암시한다. 이는 또한 행동이 환경을 변화시키고 변화시킨 환경으로부터 끊임없이 정보를 받아 우월한 학습에 도달한다는 강화학습과도 관련 있고 (최첨단 LLM이 모두 강화학습으로 훈련된다는 점과도 관련이 있다), OpenAI 등 프론티어 랩에서는 더 나은 reasoning을 위해 이런 후처리 작업에 공을 들이고 있다. 우리가 직관적으로 여기는 순차게임의 우월성이 수학적으로는 덜 연구가 된 듯하여 이를 더 깊게 들여다 보는 것도 의미가 있을 것 같다.
입력: 2026.03.10 14:31
'▶ 자연과학 > ▷ 논리학' 카테고리의 다른 글
| 【논리학】 논리학 목차 (0) | 2026.02.22 |
|---|---|
| 【논리학】 하루끝 논리퀴즈 40제 (0) | 2026.02.22 |
| 【논리학】 수학 논리 문제 [41~60] (1) | 2025.01.21 |
| 【논리학】 수학 논리 문제 [21~40] (7) | 2023.10.12 |
| 【논리학】 수학 논리 문제 [01~20] (13) | 2023.09.09 |


최근댓글