11강. 강화학습(reinforcement learning; RL)
추천글 : 【알고리즘】 알고리즘 목차
1. 개요 [본문]
2. Markov process [본문]
3. Markov decision process [본문]
4. 일반 의사결정 모형 [본문]
5. 심화 주제 [본문]
a. 강화학습 예제
1. 개요 [목차]
⑴ 정의
① (참고) supervised learning
○ 데이터 : (x, y) (단, x는 feature, y는 label)
○ 목표 : 맵핑 함수 x → y의 계산
② (참고) unsupervised learning
○ 데이터 : x (단, x는 feature이고 label은 없음)
○ 목표 : x의 underlying structure에 대한 학습
③ reinforcement learning
○ 데이터 : (s, a, r, s') (단, s는 state, a는 action, r은 reward, s'은 다음 상태)
○ 목표 : 여러 시간에 걸친 reward의 총합을 최대화
⑵ 확률적 제어이론
① 요소 1. state
② 요소 2. reward
○ 정의 : state의 변화량
○ value function : 미래의 reward에 대한 기댓값을 평생 가치(생애 가치, VLT)로 나타낸 것
○ 수식화 : state s, policy π, 미래가치를 현재가치로 보정하기 위한 계수 γ에 대하여,
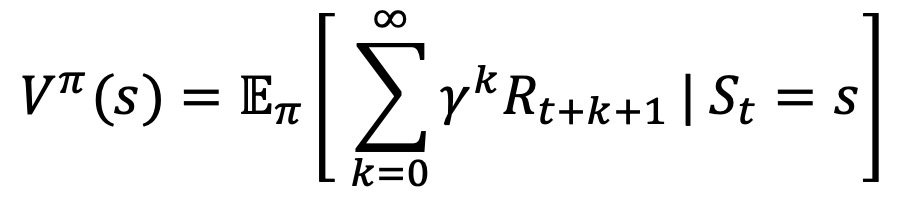
○ state가 좋은지 나쁜지를 평가하여 action을 선택하는 근거를 제공
③ 요소 3. action
④ 요소 4. policy
○ 정의 : agent의 행동. 즉, state를 입력으로 action을 출력으로 하는 맵핑
○ (참고) decision process : 어떤 과정을 거쳐 상태(state)와 행동(action), 보상(reward)이 이어지는 의사결정 문제를 다루는 일반적인 틀
○ 종류 1. deterministic policy
○ 종류 2. stochastic policy
○ 이유 1. learning에서 최적의 행위를 모르므로 exploration을 하기 위함
○ 이유 2. 최적의 상황이 stochastic한 걸 수도 있음 (예 : 가위바위보, 상대방이 역이용하는 경우)
⑤ 요소 5. model
○ 정의 : 환경(environment)의 행동
○ 주어진 state와 action에 대하여 model은 다음 state와 reward를 결정함
○ model-free method와 model-based method가 있음을 유의
⑶ 특징 : supervised learning, unsupervised learning과는 차별성이 있음
① 정답을 묵시적으로 제공받음 : reward의 형태로 제공받음
② 환경과의 상호작용을 고려해야 함 : delayed feedback 등이 문제가 됨
③ 이전의 결정이 미래의 상호작용에 영향을 줌
④ 적극적으로 정보를 얻는 알고리즘 : 강화학습은 데이터를 얻는 과정까지를 포함함
2. Markov process [목차]
⑴ 개요
① 정의 : (decision process 여부와 관계 없이) 미래 상태가 현재 상태에만 의존하고, 과거 상태에는 의존하지 않는다는 시스템

② Markov chain : Markov process 중에서 상태공간이 유한하거나 가산 무한한 것을 지칭
③ 성질 1. Chapman-Kolmogorov decomposition
④ 성질 2. linear state-space model
⑵ 그래프 이론
① strongly connected (= irreducible, communicable) : 그래프 내 임의의 노드 i에서 다른 임의의 노드 j로 도달할 수 있는 상태
② period : 특정 노드 i의 period는 노드 i에서 i로 향하는 모든 path의 최대공약수
○ 예 : 두 개의 노드 A, B가 있고 A=B와 같이 두 개의 엣지로 연결돼 있으면 각 노드의 period는 2
③ aperiodic : 모든 노드의 period가 1인 것
○ aperiodic ⊂ irreduicible
○ 예 : 각 노드가 자기 자신으로 향하는 walk가 있으면 aperiodic
④ 정상 상태(stationary state) : Pr(xn | xn-1)이 n에 무관하면 Markov process는 stationary (time-invariant)
⑤ regular
○ regular ⊂ irreduicible
○ 어떤 자연수 k에 대해, transition matrix M의 거듭제곱 Mk의 모든 원소가 양수(즉, 0이 아닌 값)인 경우
⑥ 성질 1. Perron-Frobenius theorem
⑦ 성질 2. Lyapunov equation
⑧ 성질 3. Bellman equation
⑶ 종류 1. two-state Markov chain
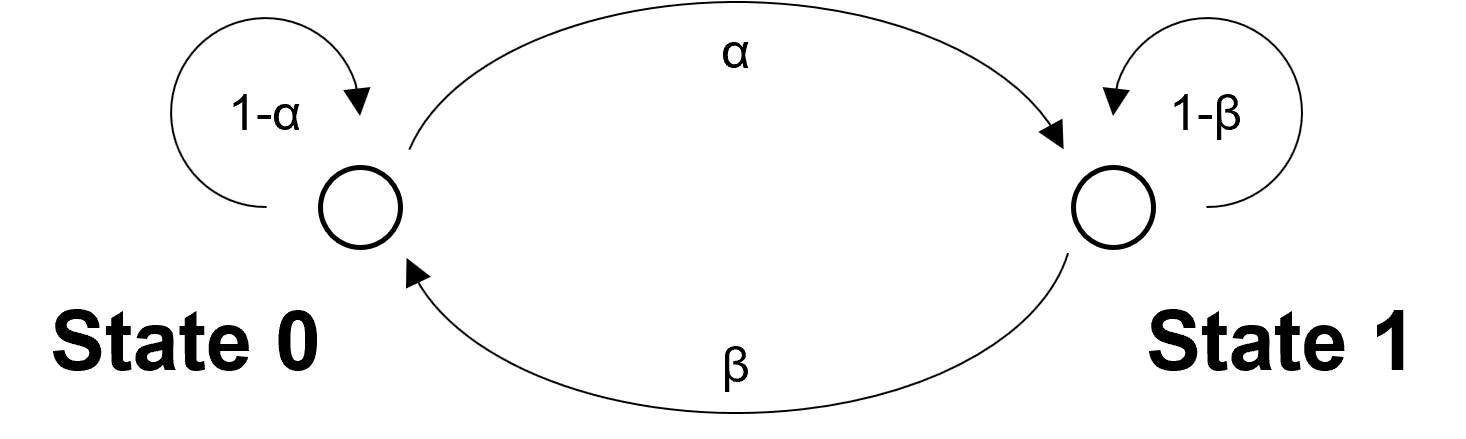

Figure. 1. two-scale Markov chain
① M : 1 step으로 state transition이 일어나는 변환
② Mn : n step으로 state transition이 일어나는 변환
③ steady-state vector : Mq = q를 만족하는 q. 즉, 고유치가 1인 고유벡터
⑷ 종류 2. HMM(hidden Markov model)
① χ = {Xi}가 Markov process이고 Yi = ϕ(Xi) (단, ϕ는 deterministic fuction)이면 y = {Yi}는 hidden Markov model
② Baum-Welch 알고리즘
○ 목적 : HMM 파라미터 학습
○ 입력 : 관측된 데이터
○ 출력 : HMM의 상태 전이 확률과 방출 확률
○ 원리 : EM(expectation maximization) 알고리즘의 일종
○ 수식화
○ Akl : 상태 k에서 상태 l로의 전이 횟수
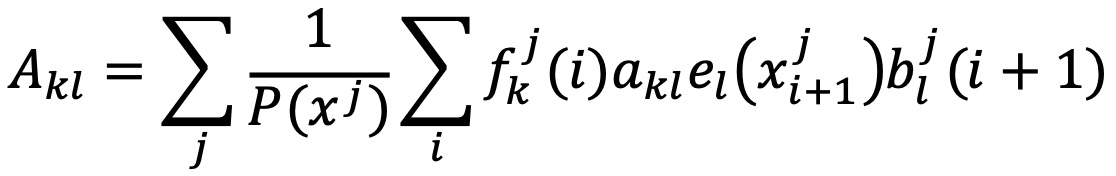
○ Ek(b) : 상태 k에서 관측값 b의 방출 횟수
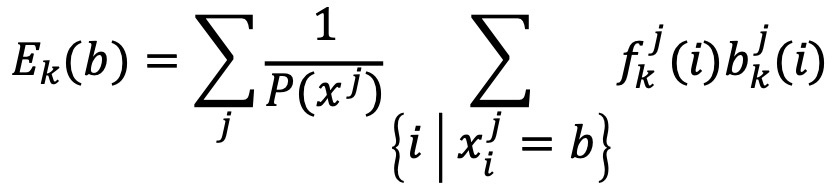
○ Bk : 상태 k의 초기 확률

③ Viterbi 알고리즘 (ref)
○ 목적 : 주어진 HMM에서 가장 가능성이 높은 숨겨진 상태의 시퀀스를 찾는 데 사용됨
○ 입력 : HMM의 파라미터와 관측된 데이터
○ N : 가능한 숨겨진 상태의 개수
○ T : 주어진 관측 데이터의 길이
○ A : 상태 전이 확률(state transition probability). akl = 상태 k에서 상태 l로 전이할 확률
○ E : 관측 확률(emission probability). ek(x) = 상태 k에서 관측 x가 나타날 확률
○ B : 초기 상태 확률(initial probability)
○ 출력 : 가장 가능성이 높은 상태 시퀀스
○ 원리 : 동적 프로그래밍(dynamic programming)을 이용해 최적의 경로를 계산
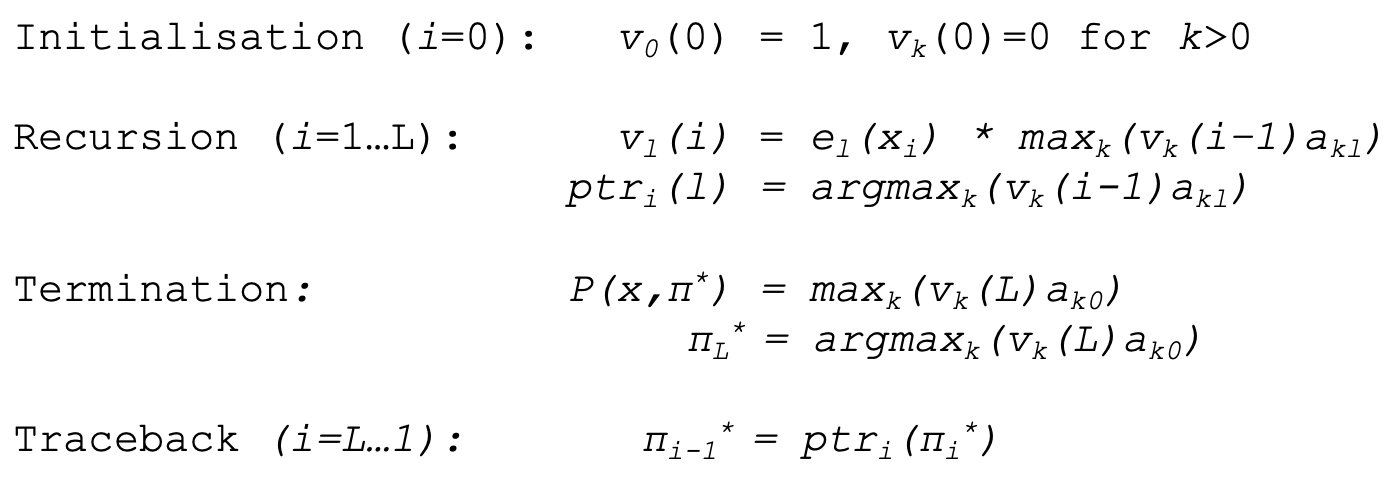
○ 단계 1. 초기화

○ bk : 상태 k의 초기 확률 P(s0 = k)
○ ek(σ) : 상태 k에서 첫 번째 관측 σ가 나올 확률 P(x0 | s0 = k)
○ 단계 2. 재귀(recursion)
○ 각 시점 i = 1, ···, T까지 모든 상태에 대해 이전 시점에서 온 최대 확률을 계산 : 다음과 같이 이전 상태에 대한 점화식이 성립

○ 가장 가능성이 높은 이전 상태를 저장하는 backpointer (ptr) 계산

○ ptri(l)은 현재 상태 l로 오는 데 가장 높은 확률을 갖는 이전 상태 k를 저장하는 역할을 함
○ 단계 3. 종료(termination)
○ 최종 시점에서 가장 높은 확률을 선택

○ 최적 상태 시퀀스의 마지막 상태를 결정

○ vk(i - 1) : 이전 시점 i - 1에서 상태 k에 있었을 때의 최적 확률값
○ akl : 상태 k에서 l로 전이할 확률
○ 단계 4. 역추적(traceback)
○ i = T, ···, 1에 대해 ptr 배열을 따라가면서 최적 경로를 복원

○ 예시

Figure. 2. Viterbi 알고리즘 예시
○ 파이썬 코드
class HMM(object):
def __init__(self, alphabet, hidden_states, A=None, E=None, B=None):
self._alphabet = set(alphabet)
self._hidden_states = set(hidden_states)
self._transitions = A
self._emissions = E
self._initial = B
def _emit(self, cur_state, symbol):
return self._emissions[cur_state][symbol]
def _transition(self, cur_state, next_state):
return self._transitions[cur_state][next_state]
def _init(self, cur_state):
return self._initial[cur_state]
def _states(self):
for k in self._hidden_states:
yield k
def draw(self, filename='hmm'):
nodes = list(self._hidden_states) + ['β']
def get_children(node):
return self._initial.keys() if node == 'β' else self._transitions[node].keys()
def get_edge_label(pred, succ):
return (self._initial if pred == 'β' else self._transitions[pred])[succ]
def get_node_shape(node):
return 'circle' if node == 'β' else 'box'
def get_node_label(node):
if node == 'β':
return 'β'
else:
return r'\n'.join([node, ''] + [
f"{e}: {p}" for e, p in self._emissions[node].items()
])
graphviz(nodes, get_children, filename=filename,
get_edge_label=get_edge_label,
get_node_label=get_node_label,
get_node_shape=get_node_shape,
rankdir='LR')
def viterbi(self, sequence):
trellis = {}
traceback = []
for state in self._states():
trellis[state] = np.log10(self._init(state)) + np.log10(self._emit(state, sequence[0]))
for t in range(1, len(sequence)):
trellis_next = {}
traceback_next = {}
for next_state in self._states():
k={}
for cur_state in self._states():
k[cur_state] = trellis[cur_state] + np.log10(self._transition(cur_state, next_state))
argmaxk = max(k, key=k.get)
trellis_next[next_state] = np.log10(self._emit(next_state, sequence[t])) + k[argmaxk]
traceback_next[next_state] = argmaxk
trellis = trellis_next
traceback.append(traceback_next)
max_final_state = max(trellis, key=trellis.get)
max_final_prob = trellis[max_final_state]
result = [max_final_state]
for t in reversed(range(len(sequence)-1)):
result.append(traceback[t][max_final_state])
max_final_state = traceback[t][max_final_state]
return result[::-1]
④ 종류 1. PSSM : 단순한 HMM 구조
⑤ 종류 2. profile HMM : PSSM에 비해 다음과 같은 장점을 가짐
○ profile HMM 모식도

Figure. 3. profile HMM 모식도
○ M, I, D는 각각 match, insertion, deletion을 나타냄
○ Mi는 Mi+1, Ii, Di+1로 갈 수 있음
○ Ii는 Mi+1, Ii, Di+1로 갈 수 있음
○ Di는 Mi+1, Ii, Di+1로 갈 수 있음
○ 장점 1. insertion, deletion을 모델링할 수 있음
○ 장점 2. transition은 유효한 상태 간 이동으로 제한됨
○ 장점 3. 상태 간 경계가 잘 정의됨
⑸ 종류 3. Markov chain Monte Carlo (MCMC)
① 정의 : 복잡한 확률 분포를 따르는 Markov chain으로부터 샘플을 생성하기 위해 사용하는 방법
② 방법 1. Metropolis-Hastings
○ 현재 상태에서 새로운 후보 샘플을 생성 → 후보 샘플을 수락 또는 거절 → 수락될 때만 새로운 상태로 전환됨
③ 방법 2. Gibbs sampling

④ 방법 3. importance/rejection sampling
⑤ 방법 4. reversible jump MCMC
○ 방법 1, 2와 같은 일반적인 MCMC는 고정된 차원의 매개변수 공간에서 확률 분포를 샘플링하는 알고리즘
○ reversible jump MCMC는 가변 차원의 매개변수 공간에서 작동 : 샘플링 중에 매개변수의 차원이 동적으로 변함
3. Markov decision process (MDP) [목차]
⑴ 개요
① decision process 중 미래가 오직 현재 상태에만 의존하는 경우
② 사실상 거의 대부분의 문제 상황이 Markov decision process에 해당함
③ 모식도 : transition과 관련하여, t+1에서의 상태가 오직 t에서의 상태의 함수로 결정되는 것

Figure. 4. MDP에서 agent-environment interaction
○ state : st ∈ S
○ action : at ∈ A
○ reward : rt ∈ R(st, at)
○ policy : at ~ π(· | st)
○ transition : (st+1, rt+1) ~ P(· | st, at)
④ 최적화 해 V(s)의 존재성

○ 전제 1. Markov property
○ 전제 2. stationary assumption
○ 전제 3. no distributional shift
⑵ 종류 1. Q-learning
① Q-learning (Watkins, 1989)
○ 개요
○ 데이터로부터 Q-function(action-value function) 자체를 학습하는 것
○ 모델에 의존하지 않음(off-policy) : 즉 전이행렬 P(x' | x, u)이 알려져 있지 않음
○ 보상 R(s, a)은 알려져 있음
○ value iteration의 예
○ 수식화 : 다음 상태 j가 확정되므로 전이확률 부분이 사라짐

○ 단계 1. 모든 state / action pair의 추정량을 초기화 : Q̂(x, u) = 0
○ 단계 2. 랜덤한 action u를 취함
○ 단계 3. 다음 상태 x'를 관찰하고 환경으로부터 R(x', u)를 받음 : 기대보상이 아닌 실현된 보상임을 유의
○ 단계 4. Q̂(x, u)를 업데이트
○ 보충
○ 모델 자체를 학습 시 |𝒮|2|𝒜|의 메모리가 필요하지만, Q-learning은 |𝒮| × |𝒜|의 메모리만 있으면 됨
○ TD(temporal difference) learning이라고도 함
○ Q-learning 수렴성 증명 : pseudo-contraction mapping

② average-reward Q-learning

③ SARSA (state-action-reward-state-action; ε-greedy, epsilon greedy) (Rummery & Niranjan, 1994)
○ 개요
○ 정책에 의존함(on-policy)
○ 데이터가 없을 때 policy를 고르며 새로이 데이터를 수집함
○ 수식화
○ 단계 1. 모든 state / action pair의 추정량을 초기화 : Q̂(x, u) = 0
○ 단계 2. k 단계에서 1 - εk의 확률로 uk ∈ arg maxv Q̂(xk, v)를 취하고, εk의 확률로 random action을 취함
○ 단계 3. 다음 상태 x'를 관찰하고 환경으로부터 R(x', u)를 받음 : 기대보상이 아닌 실현된 보상임을 유의
○ 단계 4. Q̂(x, u)를 업데이트

○ 단계 5. k → ∞이 됨에 따라 εk를 0으로 보냄 : 이때 볼츠만 분포(T → 0; temperature annealing)를 쓸 수도 있음

○ Q-learning과의 비교
○ 타깃 정책(target policy) : 학습하려는 정책
○ 행동 정책(behavior policy) : 샘플(경험)을 생성하기 위해 실제로 사용하는 정책
○ Q-learning : 타깃 정책 = 최적 정책, 행동 정책 = 각 행동이 무한히 자주 선택되도록 하는 어떤 정책이든 가능
○ SARSA : 타깃 정책 = ε-탐욕(ε-greedy) 정책, 행동 정책 = ε-탐욕 정책
○ 보충 1. 사실 behavior 정책으로 ε-greedy를 쓴다고 SARSA인 것은 아니고 target 정책이 무엇이냐가 중요함
○ 보충 2. off-policy라는 말은 데이터를 어떤 정책으로 모았든, 업데이트는 greedy 타깃(max) 기준으로 한다는 뜻
○ 보충 3. behavior가 완전 greedy(ε=0)이면 SARSA의 Q(s', a')에서 a' = argmax가 되므로 타겟이 같아져서 Q-learning과 SARSA의 식이 동일해짐
④ Q-learning with linear function approximation
○ 취지 : Q-learning의 메모리 공간은 |𝒮| × |𝒜|인 반면, linear function approximation의 경우 M ≪ |𝒮| × |𝒜|
○ 수식화 : temporal difference의 제곱인 δk2은 언제나 양수라는 이점이 있음

○ 의의 : 고정 정책 + on-policy 샘플링이면 어떤 의미의 수렴성이 성립함

○ 예시 : 테트리스 게임 (code)
○ 문제점 : 조건이 깨지면 (예 : off-policy, 잘못된 가중치로 업데이트) 발산할 수 있음

⑶ 종류 2. DQN
① Q-learning with nonlinear function approximation
○ 수식화 : Bellman equation으로 loss function을 구성

○ 문제점 : local optima, 트레이닝 중의 불안정성
② 경험 리플레이(experience replay, replay buffer)
○ 정의 : 에이전트가 환경에서 겪은 경험을 저장해두는 메모리. 보통 한 스텝을 (s, a, r, s', done)의 형태로 저장함
○ 취지 : 강화학습에서 데이터는 (y1, (x1, u1)) → (y2, (x2, u2)) → (y3, (x3, u3)) → ···와 같이 연속된 샘플이므로 서로 상관성이 높고 분포도 계속 변함. 그런데 딥러닝(SGD)은 보통 샘플이 i.i.d.일 때 훨씬 안정적으로 잘 돌아가므로, 상관성이 높은 데이터 하에서는 업데이트가 한쪽으로 튀면서 발산/진동하기 쉬움
○ 학습할 때는 지금 막 한 경험만을 업데이트하지 않고, 버퍼에 쌓인 것들 중에서 무작위로 몇 개를 뽑아서 신경망을 업데이트하여 딥러닝(SGD)이 좋아하는 i.i.d.에 가깝게 만들어줌 → local optima 방지, 학습 안정성 개선
○ 경험 리플레이는 state를 저장하지 action을 저장하지 않음
③ DQN(deep Q-network)
○ 정의 : Q learning을 deep learning으로 구현한 것. 종종 off-policy로 구현됨
○ online network (Q-network) : 지금 학습 중인 네트워크. 현재 파라미터 θ로 Q(s, a; θ)를 출력하고, 이걸로 행동 선택(ε-greedy)도 하고 SGD로 계속 업데이트됨
○ target network : online network를 복사해 둔 느리게 변하는 네트워크. 파라미터 θ-로 Q(s, a; θ-)를 출력해서 타겟 값 y = r + α maxa' Q(s', a'; θ-)을 만들 때 사용함. 일정 주기마다 θ- ← θ (hard update)를 하거나 조금씩 따라가게 해서 타겟을 안정화함
○ 경험 리플레이와의 비교 : 둘 다 학습을 안정화한다는 같은 목표를 가진 서로 다른 장치
○ 경험 리플레이 : 데이터를 섞어서(i.i.d.에 가깝게) 샘플 상관성과 분포 변화 문제를 줄임
○ DQN : 타겟 y = r + α max Q(s', a')를 만들 때 쓰는 Q가 계속 흔들리면 발산하기 쉬우니, 타겟을 계산하는 네트워크를 느리게 업데이트해서 움직이는 목표 문제를 줄임
○ SGD : yk를 레이블처럼 간주하기 위해 yk가 w에 대한 함수라는 사실을 무시

○ mini-batch SGD : 리플레이 버퍼로부터 샘플링된 mini-batch를 이용

○ Pytorch 상의 구현

Figure. 5. Pytorch 상의 구현
○ 왼쪽 (대안형) : forward(state, action) -> q_scalar (batch, 1). 가능한 행동을 전부 넣어서 Q(s,1), Q(s,2), ···를 여러 번 forward 해서 비교해야 한다는 단점이 있음
○ 오른쪽 (DQN 일반형) : forward(state) -> q_values (batch, num_actions). 한 번 forward를 한 뒤 argmax를 하면 되므로 행동 선택이 쉽고, 이는 계산 효율이 좋음. 또한, 앞쪽 hidden layer를 공유하니까, 어떤 행동의 학습 신호가 공유 표현을 바꾸면서 다른 행동 Q에도 간접 영향이 감 (coupling)
random.sample(self.replay buffer, batch size)
next state values = target net(next states).max(1)[0]
target values= rewards + gamma × next state values.detach()
loss = nn.MSELoss()(state action values, target values)
optimizer.zerograd(); loss.backward(); optimizer.step()
○ 수많은 게임에 적용됨 : Cartpole 문제 (code), Atari 2600 (2013), AlphaGo (2016) 등
④ DDQN(double Q-learning)
○ Thrun and Schwartz (1993) : Q-learning은 종종 특정 상태 하에서의 action value를 과대평가(overestimate). 이는 같은 네트워크가 선택과 평가를 동시에 하기 때문

○ double Q-learning (van Hasselt, 2010)
○ 정의 : 두 개의 Q-function(각각 파라미터를 w, w'으로 표시)을 학습한 뒤 이 둘의 평균을 취하면 overestimation 문제 해결. 이때 online network은 action을 고르기 위해 있고, target network는 값을 evaluate
○ 원리 : double estimator는 underestimator

○ 수식화

○ Q-learning vs double Q-learning (Weng et al, 2020) : Q-learning의 learning rate가 βk = c / k이고 double Q-learning의 learning rate가 βk = 2c / k이며, linear function approximation을 고려하면 다음을 얻을 수 있음. double Q-learning의 learning rate가 더 크기 때문에 더 빠르게 수렴
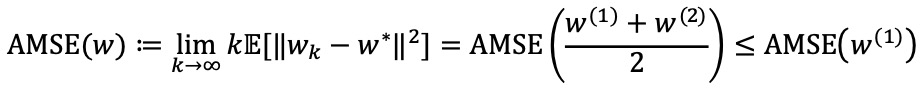
○ 예시 : JAX 상에서 DQN의 overestimation과 DDQN (code)
○ clipped double Q-learning (Fujimoto, van Hoof, David Meger, 2018)
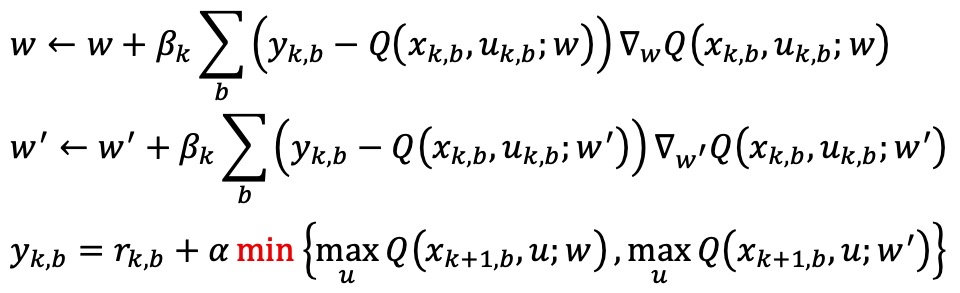
⑤ Dueling DDQN (Wang et al, 2016)

Figure. 6. Dueling DDQN
○ 정의 : advantage function A(s, a) := Q(s, a) - V(s)에 대하여, Q(s, u; w, wv, wa) = V(x; w, wv) + A(x, u; w, wa)를 이용하여 V, A를 각각 예측하는 모델을 만든 뒤 나중에 합치는 것
○ 취지 : 최적 행동을 제외하면 모든 행동이 중요한 건 아님. A(s, a)는 상태 s에 대하여 행동들을 대조(contrast)할 수 있음
○ 비식별성(unidentifiability) 문제 : Q(s, a) = V(s) + A(s, a) = (V(s) + c) + (A(s, a) - c), c ∈ ℝ처럼 해가 무수히 많이 나옴
○ 해결방법 1. substract max : Q(x, u; w) = V(x; w) + (A(x, u; w) - maxv A(x, v; w))
○ greedy policy에서 Q(x, a*) = V(x)이므로 A가 최적 정책에서 0이 되도록 강제함
○ 해결방법 2. substract mean : Q(x, u; w) = V(x; w) + (A(x, u; w) - (1/|𝒜|) ∑v A(x, v; w))
○ 장점 : 최적화 안정성을 높임. 비식별성 문제는 해결
○ 단점 : substract mean을 쓰면 V가 V*가 아니라 평균 Q라는 다른 baseline이 되어버려서 V, A의 의미가 원래 V*, A*와 다름
○ 예시 : CartPole (code)
⑥ multi-step target (Sutton & Barto, 1998)
○ Q(xk, uk) = 𝔼[r(xk, uk)] + αr(xk+1, π*(xk+1)) + ··· + αn-1r(xk+n-1, π*(xk+n-1)) + αn maxv Q(xk+n, v)
○ SARSA with multi-step target (슬라이딩 윈도우 방식) : (rk(n) + αn maxv Q(xk+n, v; w) - Q(xk, uk; w))2를 손실함수로 둠
⑦ prioritized DDQN (prioritized replay, Schaul et al., 2016)
○ 정의 : 정보이론의 surprisal을 이용하여 경험에 가중치를 부여
○ 단계 1. 새로운 경험이 추가되면 가장 높은 우선순위인 zmax를 부여
○ 단계 2. m개의 경험을 토대로 pk = zk / ∑i zi를 계산
○ 단계 3. 경험 k가 샘플링됐다면 이것의 가중치 k의 변화량을 다음과 같이 정의

⑧ distributed DQN (Bellemare et al., 2017)

⑨ noisy DQN
⑩ DON (deep O-network)
⑪ 결론 : 이들을 모두 응용하면 좋은 퍼포먼스를 얻을 수 있음

Figure. 7. rainbow
⑷ 종류 3. actor-critic
① 일반적인 actor-critic
○ 정의 : 일반화된 policy iteration. policy π(s)를 직접 학습하는 것
○ 취지
○ Q-learning은 state가 continuous해도 되는 반면 action은 discrete해야 함
○ actor-critic은 action 및 state가 continuous해도 됨
○ 일반적으로 action space가 수십 개면 DQN을 쓰고, 그 이상이면 policy gradient를 사용함
○ DQN은 input이 x, 출력이 u이지만, actor-critic은 입력이 x, u이고 출력이 Q(x, u) (∵ action space가 무한하므로)
○ 구성요소 1. critic
○ 현재/개선된 policy를 평가하거나 학습 신호를 주는 쪽
○ TD(λ), double-Q, clipped double-Q
○ 구성요소 2. actor
○ policy를 개선 하는 쪽
○ 현재 Q 함수에 기반한 ε-greedy 또는 policy-gradient
○ 구성요소 3. parameterized policy : πw(u | x)
○ 과정 예시
○ 단계 1. frame을 받음
○ 단계 2. P(action)을 얻기 위해 forward를 propagate함
○ 단계 3. P(action)으로부터 a를 샘플링
○ 단계 4. 게임의 나머지를 진행
○ 단계 5. 만약 게임에서 이기면 ∇θ 방향으로 진행
○ 단계 6. 만약 게임에서 지면 -∇θ 방향으로 진행
○ 종류 1. on-policy actor-critic
○ actor가 따르는 policy = 데이터를 모으는 policy
○ 즉, behavioral policy = target policy
○ 종류 2. off-policy actor-critic
○ actor는 보통 target policy
○ 데이터는 replay buffer 등에 저장된 behavior policy로부터 옴
○ critic은 이 데이터를 사용해 target policy를 평가/개선하는데 필요한 값을 학습
② A3C(asynchronous advantage actor-critic)
③ policy gradient theorem

○ ρw : discounted state distribution (또는 geometric distribution, discounted occupancy measure)
○ ∇w log πw(u | x) : score function
○ Gibbs 정책
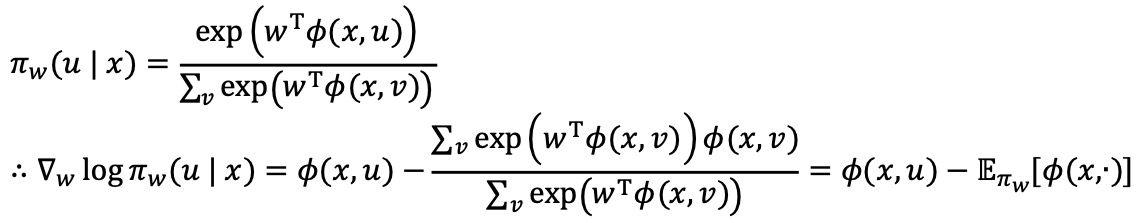
○ Gaussian 정책 : ∇w log πw(u | x) = (u - μ(x)) ϕ(x) / σ2, μ(x) = ϕT(x) w
④ REINFORCE (Williams, 1988, 1992)

○ Q-function을 추정하기 위해 Monte Carlo 사용
○ on-policy
○ 분산이 크다는 단점
○ 예시 : CartPole (code)
⑤ variance reduction theorem
○ 정의 : 주어진 F(x)에 대하여 𝔼[ϕ(x)] = 0이고 F(x)와 높은 상관성을 가지는 ϕ(x)를 이용해 Var(F(x) - ϕ(x))의 분산을 줄이는 방법
○ policy gradient theorem에서의 적용
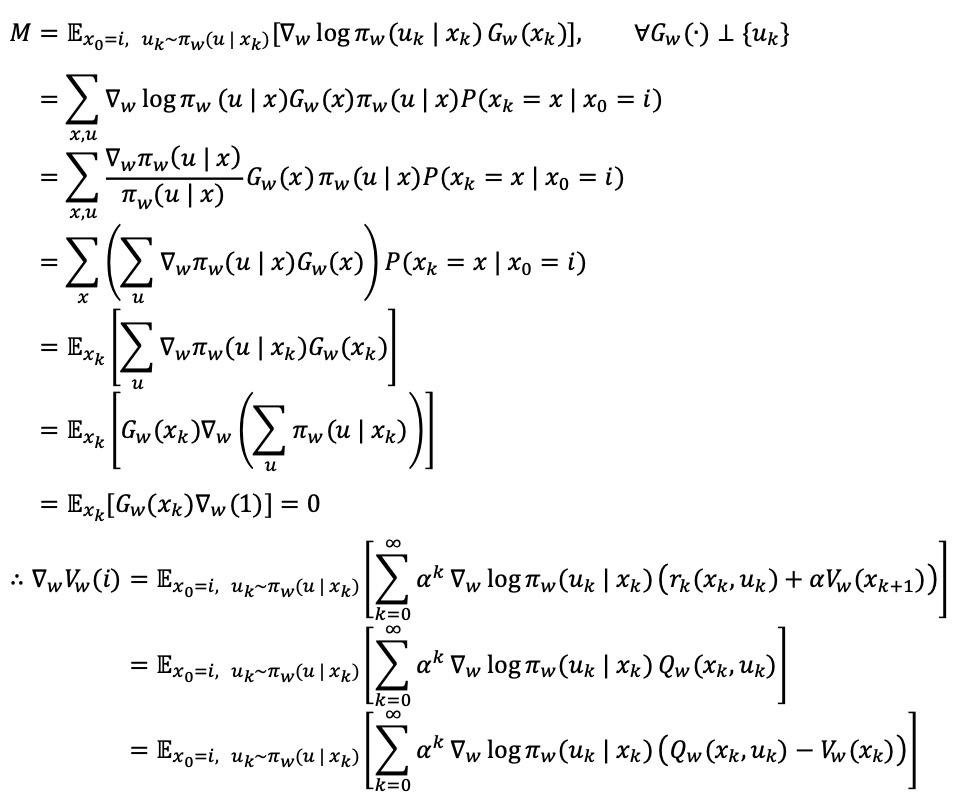
○ Gw(xk)가 action-independent여야 하는데 xk-1과 의존하는 건 상관 없지만 xk+1과 의존하게 되면 uk의 정보를 암시하므로 부적절
⑥ NPG(natural policy gradient)
○ policy gadient theorem은 일종의 최적화 알고리즘 : Euclidean. 2차 항이 없으면 ±∞에서 최대, 최소

○ NPG (Kakade et al., 2001)

○ PG의 수렴성 (Mei et al., 2020) : 상태와 행동 집합이 유한한 tabular data 기준으로,

○ β = (1 - α)3 / 8
○ S : 상태의 개수. 일반적으로 매우 크므로 PG의 수렴성 논증에서 문제가 됨
○ ρ : discounted state distribution
○ c : 상수
○ d : 초기 조건의 분포
○ NPG의 수렴성 (Agarwal, 2020) : 상태와 행동 집합이 유한한 tabular data 기준으로,

○ β = (1 - α)2 log |𝒜|
○ t : 반복수
○ NPG + entropy regularization

○ 정책 π를 보통 다음과 같이 설정함

○ β = (1 - α) / τ로 두면, 위 정책은 soft policy iteration (≃ softmax policy)가 됨
○ τ → 0으로 보내면 soft policy iteration은 다시 policy iteration이 됨
⑦ TRPO(trust region policy optimization)
○ performance difference lemma (Kakade & Langford, 2002)

○ local approximation

○ TRPO (Schulman et al., 2015)

○ 서로 다른 learning rate β 하에 TRPO = NPG
○ learning rate β는 제약조건을 만족하도록 백트래킹 선형 탐색(backtracking line search)을 통해 선택됨
○ KL divergence 제약은 정책이 너무 빠르게 바뀌는 것을 제약함
○ monotonic improvement theorem : 적절한 learning rate 하에 Vwk+1(x0) ≥ Vwk(x0)가 성립함
⑧ PPO(proximal policy optimization)
○ 취지 : NPG와 TRPO는 Fisher information matrix의 역행렬 계산을 요하므로 (즉, 2nd order method이므로) 계산 비용이 큼
○ PPO : 1st order method

○ PPO-CLIP (clipped PPO) : 보수적으로 모델이 덜 변화하도록 min을 사용. 두 번째 항의 비례계수는 1로부터 ϵ 이상 커지면 1±ϵ가 되도록 함

⑨ DPG(deterministic policy gradient)
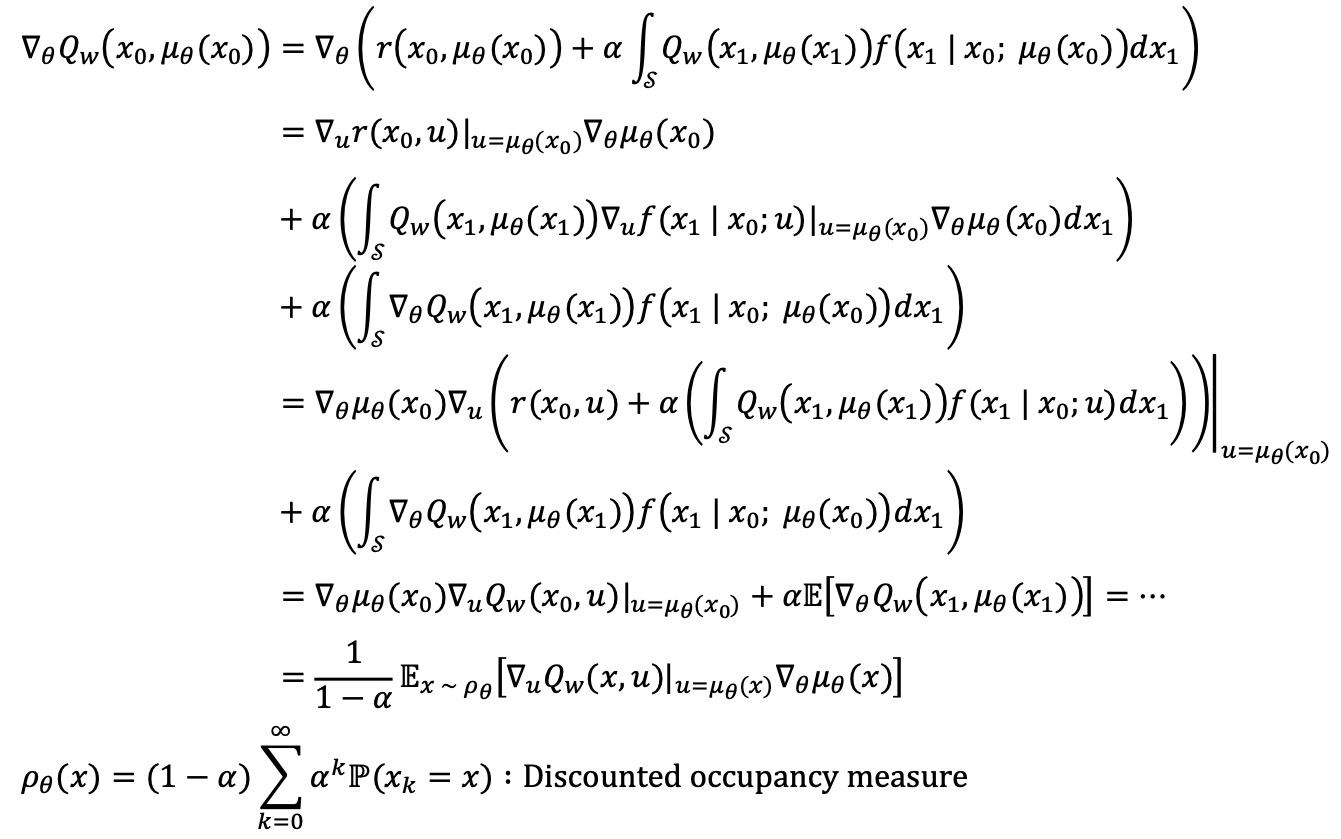
⑩ off-policy DPG

⑪ DDPG(deep DPG) : 다음과 같이 손실함수를 정의하여 역전파를 함

⑫ TD3(twin delayed DDPG) (Fujimoto, van Hoof, Meger, 2018)
○ clipped double-Q (= twin) + DPG
def train(self, cur_time_step, episode_time_step, state, action, reward, next_state, done):
self.add_to_replay_memory(state, action, reward, next_state, done)
if len(self.replay_memory_buffer) < self.batch_size:
return
if cur_time_step % self.update_every != 0:
return
for it in range(self.update_every):
mini_batch = self.get_random_sample_from_replay_mem()
state_batch = torch.from_numpy(np.vstack([i[0] for i in mini_batch])).float().to(self.device)
action_batch = torch.from_numpy(np.vstack([i[1] for i in mini_batch])).float().to(self.device)
reward_batch = torch.from_numpy(np.vstack([i[2] for i in mini_batch])).float().to(self.device)
next_state_batch = torch.from_numpy(np.vstack([i[3] for i in mini_batch])).float().to(self.device)
done_list = torch.from_numpy(np.vstack([i[4] for i in mini_batch]).astype(np.uint8)).float().to(self.device)
with torch.no_grad():
noise = torch.randn_like(action_batch) * self.target_noise
noise = torch.clamp(noise, -self.noise_clip, self.noise_clip)
next_action = self.actor_target(next_state_batch) + noise
next_action = torch.clamp(next_action, self.action_lower_bound, self.action_upper_bound)
target_Q1, target_Q2 = self.critic_target(next_state_batch, next_action)
target_Q = torch.min(target_Q1, target_Q2)
target_Q = reward_batch + self.gamma * (1.0 - done_list) * target_Q
current_Q1, current_Q2 = self.critic(state_batch, action_batch)
loss_crt = F.mse_loss(current_Q1, target_Q) + F.mse_loss(current_Q2, target_Q)
self.crt_opt.zero_grad()
loss_crt.backward()
self.crt_opt.step()
if it % self.policy_delay == 0:
actor_action = self.actor(state_batch)
q1, q2 = self.critic(state_batch, actor_action)
loss_act = -q1.mean()
self.act_opt.zero_grad()
loss_act.backward()
self.act_opt.step()
self.soft_update_target(self.critic, self.critic_target)
self.soft_update_target(self.actor, self.actor_target)
○ 퍼포먼스가 좋음
○ 예시 : Bipedal Walker Problem (code)
⑬ CRL(contrastive reinforcement learning)
○ Bayes optimal classifier

○ 종류 1. GCRL(goal-conditioned reinforcement learning)
○ 전제

○ 방법 1. Bootstrapping / TD-learning : goal을 state처럼 간주하는 방법

○ 문제 1. Q(s, a, g) 테이블의 크기는 |𝒮| × |𝒜| × |𝒢|로 이는 |𝒢|에 비례하여 비효율적
○ 문제 2. goal 간의 shared structure를 잘 다루지 못함
○ 방법 2. occupancy-measure-based : goal을 next state처럼 간주하는 방법

○ 방법 1에서 ρ(g)는 goal sampling prior이고 방법 2에서 ρ(g)는 negative/base distribution
○ Qπ(s, a, g) ≠ Qg*(s, a)
○ Qπ(s, a, g) : 지금 쓰는 혼합 정책으로 갔을 때 g에 닿을 가능성
○ Qg(s, a) : g만 목표로 한 최적 정책이면 얼마나 잘 닿는가
○ 예 : Four Rooms Grid World
⑭ 알파제로(AlphaZero) : 바둑 기보에 의존하는 알파고(AlphaGo) 모델을 개량한 것

Figure. 8. 알파제로
○ 개요
○ search-based policy iteration
○ 일종의 actor-critic
○ actor : policy network를 바탕으로 MCTS(Monte Carlo tree search)를 수행해 더 나은 policy target을 만듦
○ critic : self-play 결과를 이용해 state value z를 학습
○ 단계 1. 한 번의 시뮬레이션에서 고정된 policy network가 prior를 제공하고 MCTS가 그 prior를 바탕으로 탐색
○ 각 상태 s에서 행동 a로 분기하는 가지는 Q-value Q(s, a)와 # of visit N(s, a) 값을 가짐

Figure. 9. MCTS의 구조
○ 단계 1-1. 다음을 계산

○ 단계 1-2. 처음 본 상태를 만나거나 종결 상태를 만나면 그 경로 상의 Q와 N을 업데이트. 이때 최종 상태가 나와 같은 색의 돌인지 아닌지에 따라 value fuction의 값을 더할지 뺄지가 정해짐. value network는 search를 돕고 학습 안정화에 기여



Figure. 10. 계산 과정 예시
○ 단계 1-3. 처음 본 상태를 만난 경우 이를 트리에 포함시키고 N(sfinal, a) = Q(sfinal, a) = 0, ∀a 로 둠
○ 단계 2. 여러 시뮬레이션 결과로 더 나은 move distribution π를 획득
○ π는 더 나은 정책 타깃으로 MCTS에 의해 만들어짐 (actor-like)

○ 단계 3. 실제 대국(self-play episode)이 끝나서 실제 게임 결과 z ∈ {-1, 0, +1}를 얻음 (critic-like)
○ 일반적인 actor-critic은 critic이 먼저 있고 actor가 그 신호로 policy gradient update하는 반면, 알파제로는 actor가 먼저 있고 대국을 통해 critic 신호를 얻는 방식 (순서가 반대)
○ self-play 데이터는 과거 network들로부터 생성될 수 있어서 넓게 보면 현재 network와 다른 policy에서 온 데이터일 수 있기 때문에 off-policy스러운 면이 있음
○ 단계 4. policy network가 (s, π, z)로 학습됨. value network는 (s, z) 쌍으로 학습됨

○ π log p는 cross-entropy 형식
○ 학습된 새 모델(self.nnet)과 이전 모델(self.pnet)을 서로 대결시킴. 새 모델이 충분히 잘하면 채택, 아니면 폐기
○ 예시 : Othello Using AlphaZero
⑸ 종류 4. reward design
① 종류 4-1. reward shaping
○ 개요
○ sparse reward인 경우 제대로 학습되지 않음
○ LLM 등의 경우 reward 정의가 어려움
○ 수식화 : reward shaping function F는 다음과 같음

○ potential-based shaping function
○ F(x, a, x') = αϕ(x') - x, ϕ : 중력퍼텐셜 같은 퍼텐셜
○ F가 potential-based shaping function이면 optimal policy는 reward shaping 이후에도 동일함
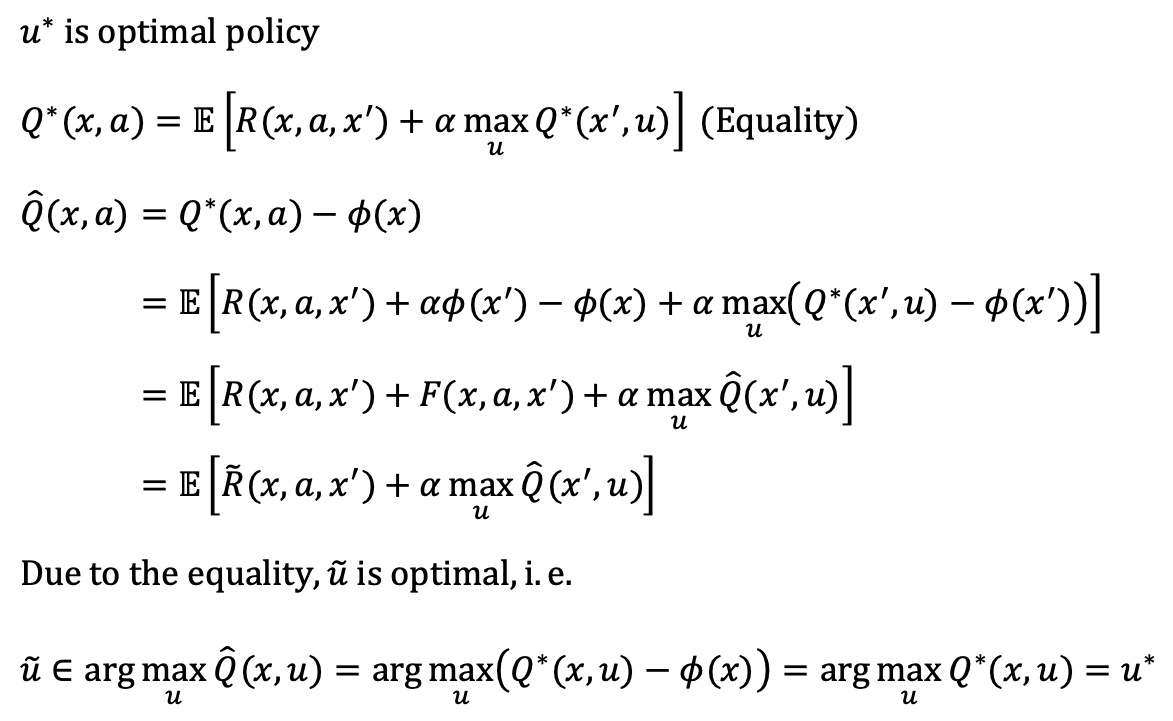
② 종류 4-2. RLHF(RL with human feedback)
○ 개요 : 기존 강화학습의 문제점은 크게 다음과 같음
○ reward misspecification
○ reward hacking : 예를 들어 로봇이 goal을 향해 가는 게 아니라 사소한 행동을 반복하여 보너스를 얻으려는 행동
○ 해결 방법 : RLHF
○ 예 1. GPT3 (RL + PPO) : pre-training (base model) → SFT (supervised fine-tuning) → RLHF

Figure. 11. GPT3 RLHF 파이프라인
○ 단계 1. pre-training 및 SFT 모델로 πref를 만듦
○ 단계 2. reward model을 학습
○ 변수 : 프롬프트 x, 모델의 답변 y
○ 문제 정의 : st = (x, y1, ···, yt), at = yt+1, π(yt+1, st) (next token prediction), r(st, at)?
○ 보상은 상대평가로 정의됨 : 사람은 절대평가보다 상대평가를 선호. 상대평가가 절대평가보다 더 안정함
○ Bradley-Terry model (1952) : (프롬프트, 답변)의 두 궤적 τ1, τ2가 주어져 있을 때 사람은 다음처럼 선호를 갖는다고 가정

○ (프롬프트, 답변)에 대한 스코어를 도출하는 보상함수를 다음과 같이 학습 : τk+, τk-는 동일한 질문에 대해 두 개의 최종 답변이고 하나는 선호, 다른 하나는 비선호

○ 단계 3. PPO-CLIP으로 강화학습
○ PPO는 보통 매 스텝마다 보상이 있어야 다루기 편함
○ 마지막 토큰 시점에는 reward model의 최종 점수

○ 중간 토큰들에는 KL penalty : πref에서 너무 멀어지지 않게 함

○ 현재 시점부터 종료까지의 누적 보상(reward-to-go) : critic은 보통 이를 예측하려고 함

○ 예 2. DPO

Figure. 12. DPO 파이프라인
○ 보상모델을 학습하지 않고 사람 선호 데이터만 보고 chosen 답변은 더 크게, reject 답변은 더 작게 만들도록 바로 학습
○ 각 프롬프트(x)마다 여러 응답(y) 후보 중 어떤 arm을 고를지 결정하는 bandit 문제처럼 봄
○ KL divergence로 regularizer를 두면 optimal policy π*는 매우 좋은 형태를 가짐

○ β↓ : reward-seeking
○ β↑ : more conservative
○ 증명

○ 정확한 r(x, y)를 알 수 없으므로 손실함수를 다음과 같이 정의함

○ RM+PPO와 DPO의 비교

Table. 1. RM+PPO와 DPO의 비교
○ 예시 : Half Cheetah
○ 예 3. zeroth-order policy optimization for RLHF

○ 예 4. SZPO(stochastic zeroth-order policy optimization) : 수렴성 있음
○ 단계 1. 각 반복 t = 1, ..., T에서 랜덤 방향 vt를 샘플링하고 θt' = θt + μtvt를 계산
○ 단계 2. 각 비교 n = 1, ..., N에서 현재 정책 πθt와 perturbed 정책 πθt'으로부터 궤적을 각각 샘플링하고 M개의 human evaluator로 ot,n,m ∈ {0, 1}을 계산 (단, t는 반복 인덱스, n은 비교 인덱스, m은 human evaluation의 수)
○ 단계 3. improved direction인 ĝt = stvt를 계산

○ 단계 4. policy를 업데이트 : θt+1 = θt + αt ĝt
○ 예 : Half Cheetah
○ 예 5. Sign-SZPO : 수렴성 있음
○ preference model이 알려지지 않을 때 st = Sign(𝔼[r(τθt') - r(τθt)])와 같이 정의
○ 수렴성이 있는 이유 : dirction과 sign이 강한 상관계수가 있기 때문
③ 종류 4-3. RLVR(RL from verifiable reward)
○ 개요
○ RLHF에서 사용하는 human annotation은 비용이 큼
○ 수학적 증명처럼 자동으로 검증할 수 있음
○ 목적함수

○ 예 1. GRPO(group relative policy optimization)
○ 단계 1. 각 초기 상태마다 현재 정책으로부터 여러 개의 출력들을 샘플링
○ 같은 초기 상태에서 나온 답변들끼리 비교하면, 질문 자체의 난이도 차이를 어느 정도 상쇄할 수 있음
○ 단계 2. 각 trajectory에 대해 verifier를 통해 검증 가능한 보상을 획득
○ 단계 3. 절대 보상을 그룹 내 상대적 advantage로 변환

○ 단계 4. 목적함수 : PPO와 유사함

○ 공통점 : policy rate, clipping, KL penalty
○ 차이점 : PPO는 advantage를 critic/value 모델에서 얻고, GRPO는 advantage를 그룹 상대 비교로 만듦
4. 일반 의사결정 모형 [목차]
⑴ MAB(multi-armed bandit) : UCB, 톰슨 샘플링 등
⑶ 논리 추론 모델
5. 심화 주제 [목차]
⑴ unsupervised learning
① benchmark : URLB
② baseline : Diversity is all you need, Forward Backward Representation
③ env : Dm_control, Maze, Hopper, Cheetah, Quadruped, Walker
⑵ online goal-conditioned reinforcement learning
① benchmark : JaxGCRL
② baseline : Contrastive Reinforcement Learning, SAC, PPO, TD3
③ env : Brax, locomotion, manipulation
⑶ offline goal-conditioned reinforcement learning
① benchmark : OGBench
② baseline : CRL, HIQL, QRL, implicit Q/V learning
③ env : locomotion, manipulation, powderworld
④ example follow-up : TMD, MQE
⑷ continual reinforcement learning
① benchmark : CORA
③ env : Atari, Procgen, Minihack, CHORES, Nethack (codebase)
④ env without benchmark : AgarCL, Jelly Bean World
⑸ open-ended reinforcement learning
① benchmark : Craftax baseline
③ env : Craftax
⑹ safe reinforcement learning
① benchmark : Omnisafe
② baseline : CPO, FOCOPS, PPO-Lagrangian and TRPO-Lagrangian
③ env : Safety-Gymnasium, Safe-Control-Gym
⑺ multi-agent reinforcement learning
① benchmark : BenchMARL
③ env : PettingZoo, VMAS
⑻ queueing network control via reinforcement learning
① benchmark : QGym
② env : DiffDiscreteEventSystem
입력: 2021.12.13 15:20
수정: 2026.02.20 23:38
'▶ 자연과학 > ▷ 알고리즘·머신러닝' 카테고리의 다른 글
| 【알고리즘】 26강. 기타 알고리즘 (0) | 2022.01.11 |
|---|---|
| 【알고리즘】 12-1강. DIP(Deep Image Prior) (0) | 2021.12.31 |
| 【알고리즘】 6강. 분류 알고리즘 (0) | 2021.12.11 |
| 【알고리즘】 11-1강. Multi-armed Bandit (MAB) (0) | 2021.12.10 |
| 【알고리즘】 7강. 차원 축소 알고리즘 (0) | 2021.12.03 |




최근댓글