18강. 회귀분석의 정규화(regularization, penalization)
추천글 : 【통계학】 통계학 목차
1. 개요 [본문]
2. MSPE [본문]
3. 기법 1. Ridge regression [본문]
4. 기법 2. Lasso regression [본문]
5. 기법 3. 엘라스틱 넷 [본문]
6. 기법 4. SelectFromModel [본문]
1. 개요 [목차]
⑴ 회귀분석의 문제점 : 주로 회귀변수가 굉장히 많은 경우에서 두드러짐
① 다중공선성(multicollinearity)
② 언더피팅(underfitting) : 모델이 flexibity가 떨어져서 주어진 데이터를 제대로 학습하지 못하는 것
③ 오버피팅(overffiting)
○ 평범한 회귀분석인 OLS 추정을 하는 경우 표본의 부정확성을 학습하여 예측력이 떨어짐
○ 학습을 시킬 때 바이어스 또한 학습시키는 게 오히려 예측력을 개선시킴
⑵ regularization (penalization)
① 회귀분석의 문제점을 해결하기 위해 파라미터에 대한 panelty 항을 추가함
② regularization을 안 하면 오버피팅이 일어나고 너무 많이 하면 언더피팅이 일어남을 유의
③ 데이터 표준화(standardization)을 같이 수행해 주어야 함
○ 값이 큰 피처는 계수도 커져서 더 강하게 규제되어 계수가 과도하게 작아질 수 있음
○ 이에 반해 값이 작은 피처는 계수도 작아져 덜 규제되어 충분히 규제되지 않을 수 있음
④ 밸리데이션 세트로 파라미터(예 : panelty 항의 가중치)를 최적화하는 과정이 포함되기도 함
⑤ regularization의 예상 결과

Figure. 1. regularization의 예상 결과
2. MSPE(mean squared prediction error) : MSE라고도 함 [목차]
⑴ 개요
① 에러(error) : e를 squared error, h를 hypothesis, f를 true function이라고 할 때,
② 종류 1. in-sample error : training error라고도 함. bias와 유사함
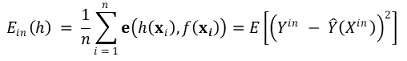
③ 종류 2. out-of-sample error : generalization error, MSPE라고도 함. variance와 유사함
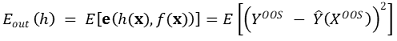
○ 1단계. 주어진 샘플을 가지고 예측모델을 생성
○ 2단계. 샘플 밖(OOS, out of sample)의 데이터 XOOS, YOOS를 이용하여 예측값과 실제값을 비교
○ 단, ŷ은 샘플 내 데이터를 통해 얻은 예측값을 의미
④ (참고) bias-variance tradeoff
⑤ 최고 예측량 : oracle predictor라고 함. E(YOOS | XOOS)
○ MSPE에서 발생된 예측 오류는 다음과 같음
○ 본질 에러(fundamental error) : 개선할 수 없음. YOOS - E(YOOS | XOOS)
○ 추정 에러(estimation error) : Ŷ(XOOS) - E(YOOS | XOOS)
⑵ MSPE 추정량
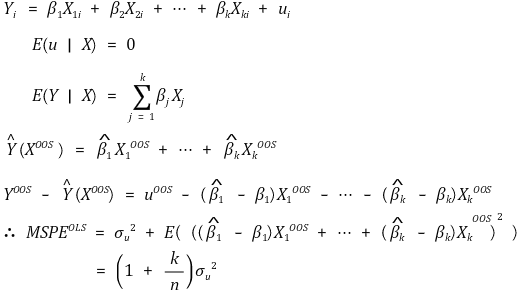
① β가 알려져 있으면 MSPE = σu2가 성립
② k/n은 클 수 있음
⑶ 가정
① 가정 1. 다중 공선성이 없을 것
② 가정 2. (XOOS, YOOS)가 동일한 모집단으로부터 랜덤하게 추출된 것일 것
⑷ 변형
① 표준화(standardization)
○ (Xi1*, ···, Xki*, Yi*)는 원본 샘플에서 추출된 값
○ Xji를 (Xji* - μXj*) / σXj*로 정의
○ 종속변수는 Yσj ← Yσj - μY*로 변형
② 수축의 원리(principle of shrinkage)

○ MSPE를 줄일 수 있음
○ 대신 편향성이 발생함 : 트레이드오프
○ 가장 유명한 예는 James-Stein estimator임
⑸ in-sample MSPE 계산 : m-fold cross validation이 주로 사용
① 1st. 주어진 샘플을 m개의 파트로 분류
② 2nd. m-1개의 파트는 파라미터를 계산하는 데 이용 : 트레이닝 데이터
③ 3rd. 나머지 1개의 파트는 퍼포먼스를 확인하는 데 사용 : 테스팅 데이터
④ 4th. 이를 서로 다른 조합에 대해 m번 반복
⑤ 5th. 평균을 취하여 최종 추정량을 결정
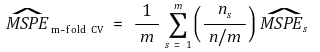
⑥ 일반적으로 10-fold cross validation이 사용됨
⑹ out-of-sample root MSPE 계산
① 다른 샘플의 데이터를 in-sample을 통해 얻은 학습 모델에 대입하여 퍼포먼스를 확인
② 다른 샘플의 데이터를 밸리데이션 세트(validation set)라고 함
3. 기법 1. Ridge regression [목차]
⑴ 개요
① 정의 : model complexity가 너무 크지 않도록 제곱의 형태로 패널티를 주는 방식. weight의 함수로 패널티를 제공
② L2 regularization이라고도 함
③ 역행렬의 부존재로 회귀분석의 해가 정의되지 않는 문제를 해결하기 위해 1962년 A. E. Hoerl에 의해 최초로 소개
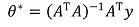
④ Gaussian distribution에 대한 MAP learning
⑵ 목적 함수(objective function)
① 단순한 형태
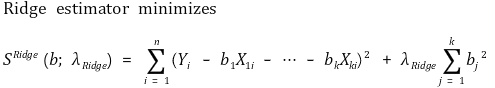
② PRSS(penalized residual sum of squares)
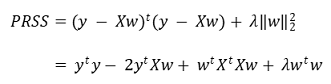
⑶ 경우 1. 회귀변수들이 상관관계가 없는 경우
① 단순한 형태 : λ = 0일 때 구한 회귀변수 β̂j에 대해 상대적으로 표현할 수 있음
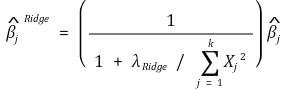
② 행렬 표현 : Ridge objective function은 convex function이기 때문에 미분을 통해 쉽게 해를 도출할 수 있음
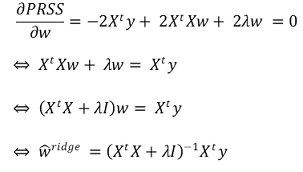
⑷ 경우 2. 회귀변수들이 상관관계가 있는 경우 : λRidge에 따른 MSPE를 살펴야 함
① bias-variance trade-off
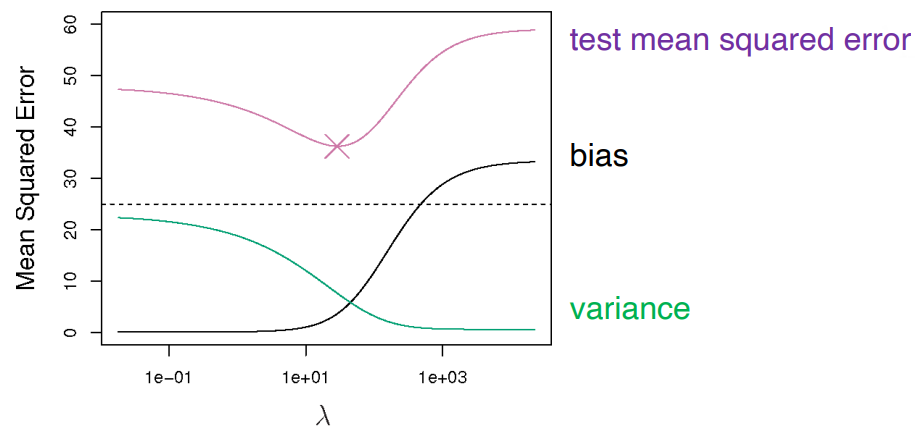
Figure. 2. 일반적인 bias-variance trade-off
② λRidge는 cross validation을 통해 계산됨
③ λRidge = 0은 in-sample 기준으로 가장 잘 들어맞지만 out-of-sample에 대해서는 잘 들어맞지 않음
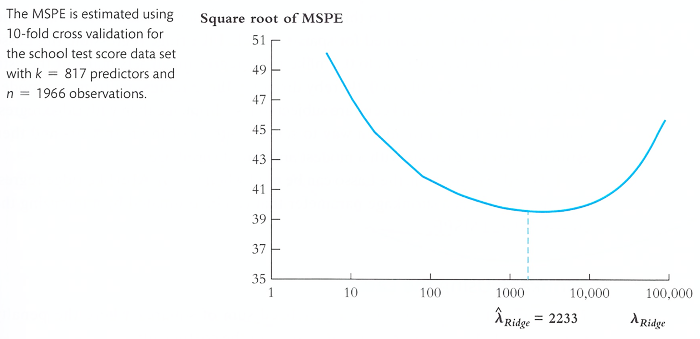
Figure. 3. λRidge에 따른 MSPE의 제곱근
⑸ Ridge regression 해의 특징
① 만일 XtX의 역함수가 없어도 λ가 있음으로 인해 역함수를 구할 수 있게 함
② 각 λ별로 한 개의 추정량이 존재함
③ λ → 0 : overfitting. linear regression solution, 즉 OLS 해에 도달함
④ λ → ∞ : underfitting. 각 계수 w는 0과 가까워짐 (∵ 계수들의 절대값이 큰 것에 대해 패널티를 부과)
⑹ 응용 1. soft order constraints : 결국 || w || ≤ C와 같은 부등식 제약이 등호 제약으로 바뀌게 됨
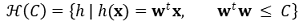
⑺ 응용 2. weight decay : || w ||는 error-term처럼 보아 일반적인 신경망 업데이트 접근 방법을 사용할 수 있음
① 일반적인 gradient descent : wt - η∇Ein(wt)
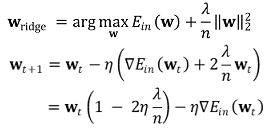
⑻ 응용 3. MAP(maximum a posterier)
① Bayes rule

② 일반적인 MAP learning : Bayes rule에서 "P(D) = 일정"인 상황을 상기
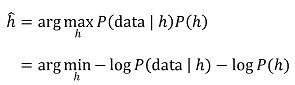
○ 정규분포를 따른다는 가정 : 단, w가 w0를 제외하고는 priori와 무관하고 작다는 가정
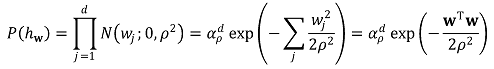
③ Ridge regression에서의 MAP learning
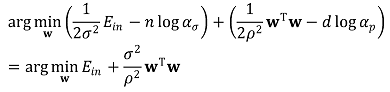
⑼ 응용 4. 다른 방법과의 비교
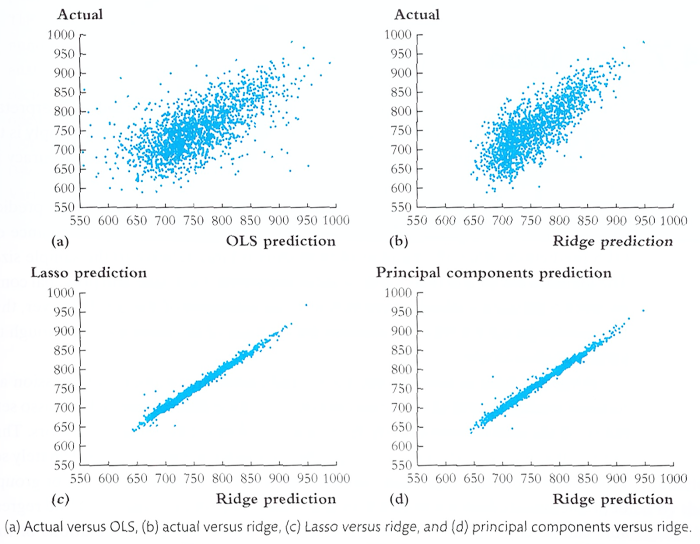
Figure. 4. 예측 퍼포먼스 비교
4. 기법 2. Lasso regression (least absolute shrinkage and selection operator) [목차]
⑴ 개요
① 정의 : model complexity가 너무 크지 않도록 절댓값의 형태로 패널티를 주는 방식. weight의 함수로 패널티를 제공
② L1 regularization이라고도 함
③ Laplacian prior에 대한 MAP learning
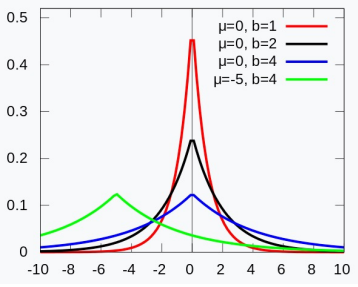
Figure. 5. Laplace probability density function
⑵ 목적 함수(objective function)
① 단순한 형태
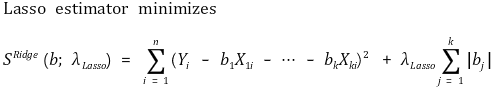
② 행렬 표현
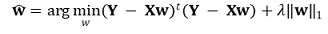
⑶ 목적함수의 해 : λLasso에 따른 MSPE를 구함
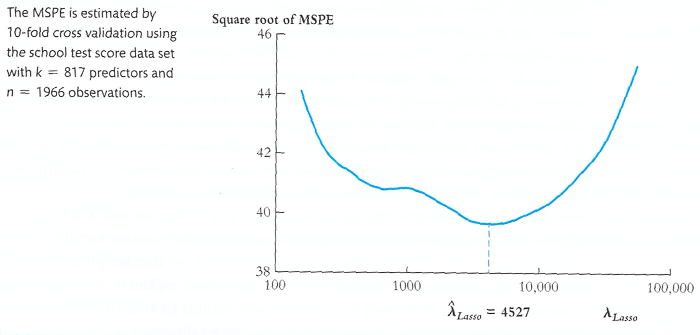
Figure. 6. λLasso에 따른 MSPE의 제곱근
① λLasso는 cross validation을 통해 계산됨
② Ridge regression에 비해 일반적인 함수 형태가 없음
⑷ 특징
① 모델이 성김 특성(sparsity property)이 있는 경우 유용 : 즉, 많은 계수들이 0인 경우
② λ → 0 : linear regression solution, 즉 OLS 해에 도달. in-sample은 가장 잘 맞고 out-of-sample은 잘 안 맞음
③ λ → ∞ : 각 계수 w는 0과 가까워짐 (∵ 계수들의 절대값이 큰 것에 대해 패널티를 부과)
⑸ 응용 1. sparsity의 원리
① Laplace prior는 덜 중요한 변수들을 딱 0으로 만듦 : 중요하지 않은 변수를 제거하는 효과
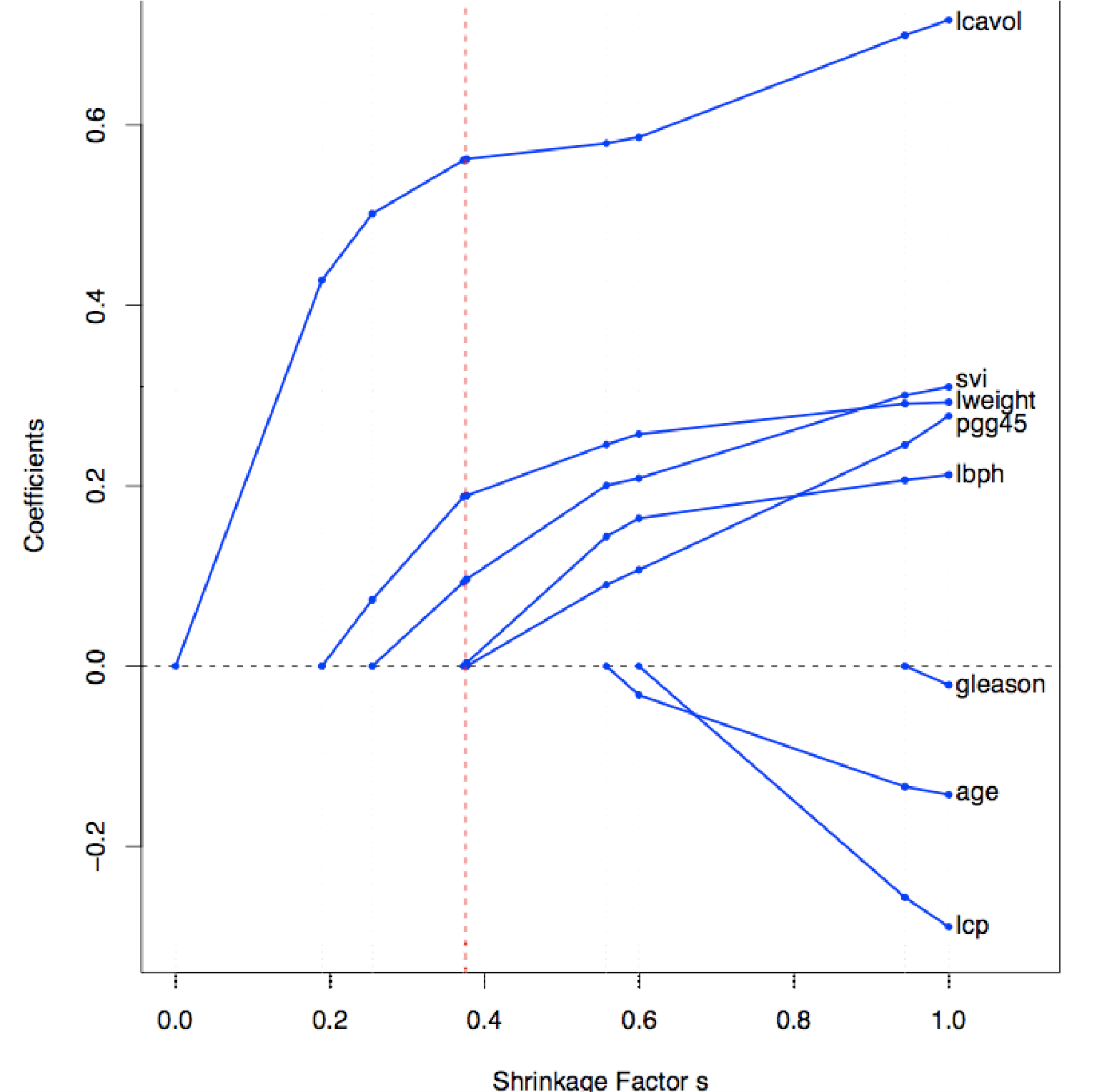
Figure. 7. shrinkage factor에 따른 각 계수의 추이
② sparsity의 원리에 대한 도식
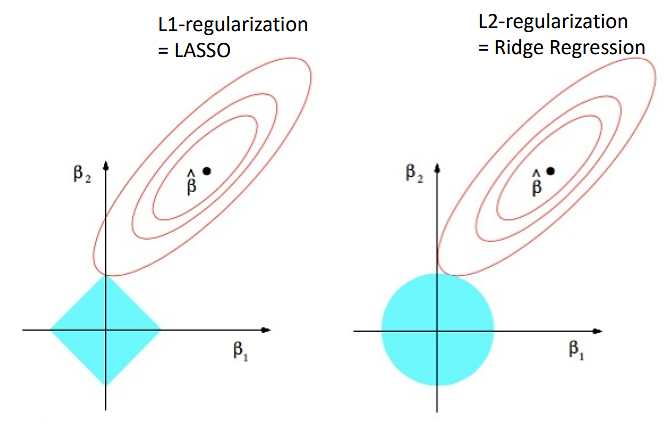
Figure. 8. Lasso regression의 sparsity에 대한 직관적인 이해
○ 붉은색 타원은 MSE(mean squared error)가 동일한 점들을 연결해 놓은 것
○ 하늘색 영역은 penalty가 일정한 점들을 연결해 놓은 것
○ λ가 증가하면 penality가 증가하므로 LASSO와 Ridge 모두 shrink함
○ Ridge의 경우 붉은색 타원과 원형 하늘색 영역이 접하는 지점에서 최적해가 생성 : 만약 접하지 않으면 붉은색 타원을 따라가다 보면 원점과 더 가까운 (penality가 더 작은) 부분이 존재함
○ LASSO의 경우 원형 하늘색 영역이 충분히 작은 경우 특정 계수가 0인 지점에서 최적해가 생성 : 뾰족한 그 지점에서 하늘색 영역의 가장자리를 따라 움직이면 붉은색 타원의 '밖' (→ MSE가 커짐)으로 벗어남
○ 이로 인해 Ridge와 달리 LASSO는 sparsity를 유도함
⑹ 응용 2. 다른 방법과의 비교
Figure. 9. 예측 퍼포먼스 비교
5. 기법 3. 엘라스틱 넷(elastic net) [목차]
⑴ 라쏘(lasso)와 릿지(ridge) 두 개를 선형 결합한 방법. 즉, 가중치 절댓값의 합과 제곱 합을 동시에 추가적인 제약조건으로 하는 방법
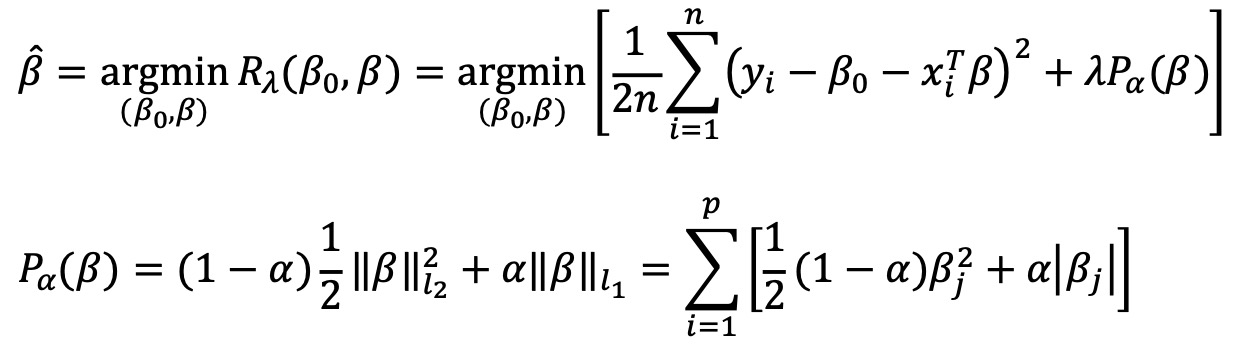
⑵ 파라미터 1. alpha (α) : L1과 L2 penalty의 혼합 비율을 조절. α = 1이면 Lasso, α = 0이면 Ridge와 동일해짐
⑶ 파라미터 2. lambda (λ) : penalty의 강도를 조절하는 파라미터. 전체 규제항에 곱해짐
6. 기법 4. SelectFromModel [목차]
⑴ 의사결정나무(decision tree) 기반 알고리즘에서 변수를 선택하는 방법
입력: 2019.12.08 12:35
수정: 2024.09.27 08:47
'▶ 자연과학 > ▷ 조합론·통계학' 카테고리의 다른 글
| 【통계학】 통계학 기초 문제 [01-20] (5) | 2024.12.24 |
|---|---|
| 【통계학】 14-8강. Cochran-Mantel-Haenszel (CMH) 검정 (7) | 2024.10.14 |
| 【통계학】 21강. 정보이론 (5) | 2024.10.07 |
| 【통계학】 14-10강. 우도비 검정과 Wilks’ phenomenon 증명 (3) | 2024.09.25 |
| 【통계학】 Optimal Transport 및 Gromov-Wasserstein 거리 이해하기 (3) | 2023.11.04 |




최근댓글